Responses API 的 WebSocket 改造:如何让 Agent 工作流提速 40%
本文基于 OpenAI 工程博客 Speeding up agentic workflows with WebSockets in the Responses API(作者 Brian Yu、Ashwin Nathan,发布于 2026-04-22)整理,在原文基础上补充了背景概念和原理说明。
当 Codex 帮你修 Bug 时,它会扫描代码库、读取文件、做修改、跑测试,这个过程背后是几十次往返的 Responses API 请求。随着模型推理速度越来越快,这些 API 请求的累计开销反而成了瓶颈。OpenAI 最近发表的博客记录了他们如何用 WebSocket 持久连接把 Agent 工作流的端到端延迟压缩了 40%。
从推理快到 API 慢
Agent 工作流的核心是一个循环:模型决定下一步动作 → 客户端执行工具调用 → 把结果传回 API → 模型继续。这个循环里的"工具调用"可以是读取文件、运行命令、搜索网页等任何操作。
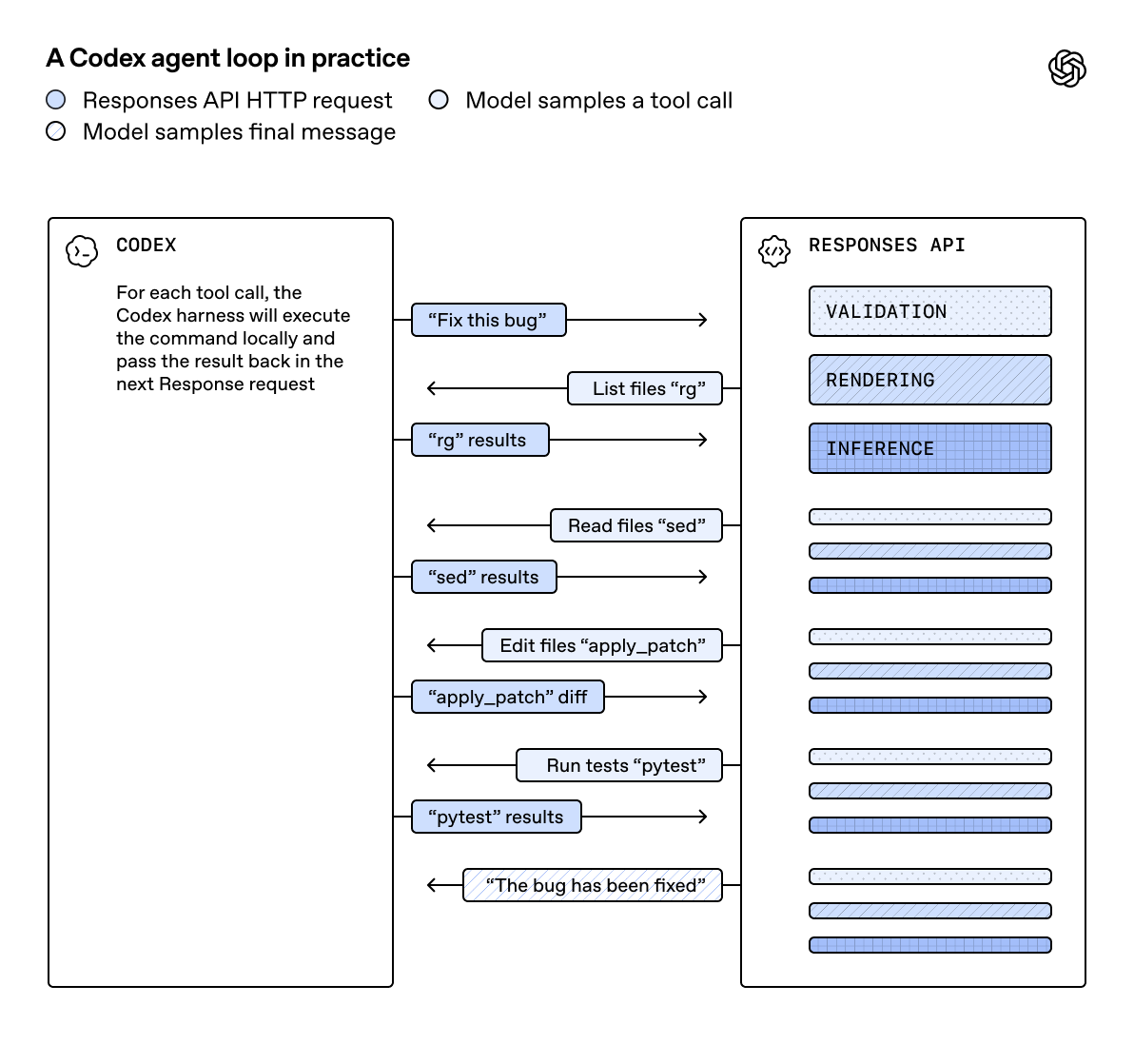
早期模型推理速度慢(GPT-5 大概 65 tokens/秒),API 服务的处理开销被推理时间完全遮蔽了,就像排队时收银员处理慢,顾客走多快根本不重要。
GPT-5.3-Codex-Spark 把推理速度提到了 1000 tokens/秒以上,快了整整一个数量级(背后是 Cerebras 专用推理芯片的优化,约等于每秒生成 500 个中文字符)。推理变得极快后情况反转了,API 服务的累计开销从"可以忽略"变成了"明显卡顿"。
OpenAI 测出这个瓶颈的构成:
- API 服务端开销:验证请求、处理对话状态
- 模型推理:GPU 生成 token
- 客户端开销:运行工具、构建上下文
推理已经足够快了,但每个请求都要重建完整的对话上下文、重新做安全检查、重新路由,这些"API 开销"累积起来,拖住了整体速度。
一次优化失败的教训
他们首先做了一轮单请求优化:
- 把 token 和配置缓存到内存,跳过重复的 tokenization
- 减少网络跳转,直接调用推理服务而不是绕路中间件
- 改进安全分类器,加快内容审核速度
这波优化把"首 token 响应时间"(TTFT,即用户发出请求到收到第一个 token 的时间)缩短了约 45%,效果明显。但问题还在,每个请求仍然要重建完整的上下文状态,对话越长,重复计算越多。
根本原因是结构性的:把每个 Agent 请求当作独立的 HTTP 请求来处理,天然就要为每个请求付出完整的上下文处理成本。
WebSocket 持久连接的设计
解决方案是改掉"每次请求都重建上下文"的结构,保持一个持久连接,在服务端缓存对话状态,新请求只发送变化的部分。
两种设计方案
团队考虑了两种实现路径:
方案 A:把整个 Agent rollout 看作一个长 Response。利用 asyncio 特性,Responses API 在采样到工具调用后在 sampling loop 中异步阻塞,向客户端发送 response.done 事件;客户端执行完工具后发回 response.append 事件,采样 loop 解除阻塞继续进行。
方案 A 的核心是:把整个 Agent rollout 看作一个长 Response,模型采样到工具调用后阻塞,等客户端执行完再继续。这借鉴了远程工具调用的模式 —— 模型调 web search 时,inference loop 阻塞、等待远程服务返回结果再继续推理。方案 A 把客户端工具执行也变成了这种方式,推理前(preinference)的工作(上下文准备、状态验证)和推理后(postinference)的工作(记账、写日志)各只做一次,中间的工具执行通过 WebSocket 往返传递。
但这个方案的原型效果虽然惊人,API 形状变化太大,开发者要把现有的 API 集成代码全部重写。
方案 B(最终选择):保持 API 形状不变,新增 previous_response_id 字段。开发者继续用 response.create 和完全相同的请求体,只是新增一个 previous_response_id 字段(由服务端生成,用于关联对话状态的标识符)。WebSocket 连接建立后,服务端缓存这个连接的对话状态,下一个请求来时直接复用。
两种方案的核心差异在于:方案 A 改了交互模式,方案 B 保持了 HTTP 请求的语义,只是把传输层换成了 WebSocket。
状态缓存里存了什么
请求带上 previous_response_id 后,服务端从缓存中取出的状态包括:
- 上一个
response对象本身 - 之前的输入和输出 items
- 工具定义和命名空间
- 已渲染的 token(避免重复 tokenization)
- 成功的模型解析/路由逻辑
基于这些缓存,请求只需要发送"新增的输入",而不是"完整的对话历史"。安全分类器和请求验证器也只需要处理新增内容,而不是全文重跑一遍。缓存有效期与连接生命周期绑定,连接断开后状态自动清除,客户端需通过新的 WebSocket 连接重新初始化。
请求之间的重叠执行
在 HTTPS 模式下,每个请求是独立的,服务端必须等前一个请求完整走完所有阶段(验证→推理前→采样→推理后),才能开始处理下一个请求,因为每个新请求进来时,服务端不知道它属于哪个对话、上下文在哪里,一切要从头重建。
WebSocket 模式下,连接建立后对话状态始终缓存在服务端内存中,新请求进来时可以直接复用。
具体来说,非阻塞的 postinference 工作(比如记账、写日志)可以单独挂起,让下一个请求的验证阶段先跑起来。而安全分类器、请求验证器只需要处理新增的输入内容,不再需要扫描完整历史,这也减少了一个串行瓶颈。
有状态的连接让服务端知道"这个请求接在哪一个上下文后面",从而把本来串行的多个请求拆散、重新排列、流水化。
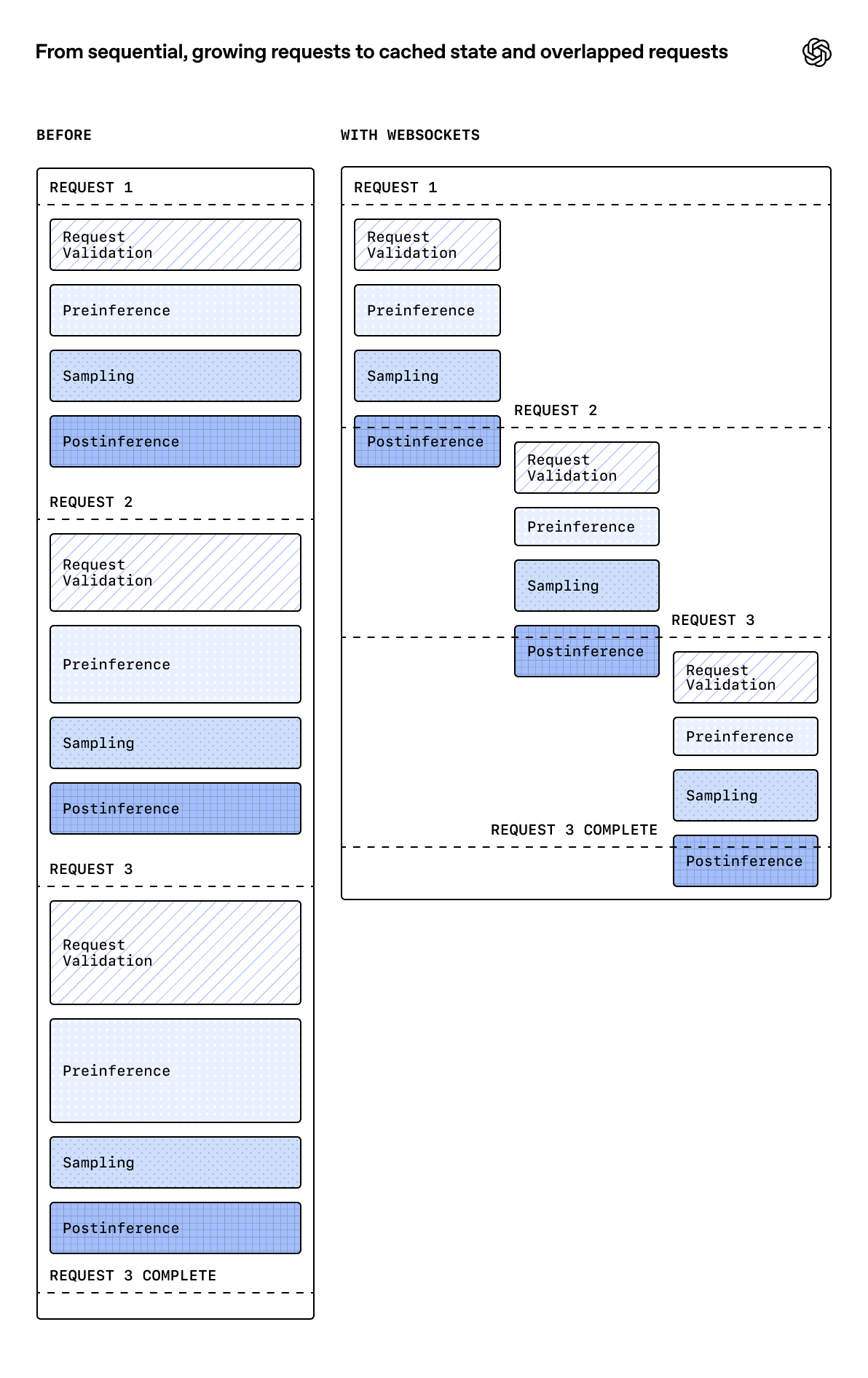
图里可以看到关键差异:传统模式下,请求按顺序经历完整的"验证→推理前→采样→推理后"才能开始下一个;WebSocket 模式下,多个请求的各阶段可以流水重叠。
为什么选 WebSocket 而不是 gRPC
团队考虑了 gRPC 双向流,但最终选了 WebSocket,核心考量是开发者体验。
WebSocket 是一个简单的消息传输协议,不需要改变 Responses API 的输入输出形状。现有的 response.create 调用加上 previous_response_id 就能工作,开发者迁移成本极低。
gRPC 双向流功能更强,但需要定义 proto 文件、生成客户端代码、改写请求逻辑,对于本来只是想"提速"而不是"换架构"的团队,这个成本不划算。
官方 API 文档:https://developers.openai.com/api/docs/guides/websocket-mode
上线效果
WebSocket 模式上线后,外部反馈和数据都验证了效果:
- Codex:大部分 Responses API 流量已迁移到 WebSocket 模式,GPT-5.3-Codex-Spark 跑到 1000 TPS,峰值到过 4000 TPS;GPT-5.4 等后续模型也受益于此优化
- Vercel AI SDK:延迟降低 40%
- Cline:多文件工作流提速 39%
- Cursor:OpenAI 模型提速最高 30%
这些数字说明,在推理速度突破之后,API 层的传输效率确实成了瓶颈,而 WebSocket 持久连接解决了这个问题。
启示
优化要随主要矛盾变化而转移。推理成为瓶颈时,优化推理;推理变快后,API 开销成了新瓶颈。这是根据实际情况调整优先级,不是顾此失彼。性能优化是持续工作,要一直跟踪瓶颈在哪里。
保持 API 兼容性是值得的工程决策。方案 A 理论上更优,但团队选了方案 B,是权衡了迁移成本和收益后的务实选择。接口的稳定性本身也是产品的一部分。
缓存设计要考虑失效场景。连接断开或超时后状态会丢失,长时间运行的 Agent 任务需要有状态恢复或重新初始化的机制。持久连接更适合"长时间、多次交互"的场景。
传输层的改进能释放模型能力的红利。GPT-5.3-Codex-Spark 能跑到 4000 TPS,但没有 WebSocket 模式的优化,这个速度会被 API 开销对冲掉。模型变强了,要把红利真正传递到用户手上,周围的工程系统也需要同步进化。