从 MiniMind 出发:Attention 拿到上下文之后,MLP 还在做什么
上一篇我们顺着 MiniMind 看 attention,重点是一个 token 不再只盯着自己,而是开始去看别的位置,决定应该听谁、记什么。到了这一步,模型内部的信息已经流动起来了。
但这还不是一个 Transformer block 的终点。一个位置把外部信息拿回来之后,并不会自动变成更好的表示——延续之前的叫法,这里说的“表示”就是模型内部那个描述 token 的向量 hidden_states。它还需要在自己的位置上,把刚收进来的内容重新整理、筛选、压缩,变成新的内部表达。
这也就是这篇想回答的问题:attention 已经拿到了上下文,为什么后面还要再来一层 MLP?
先说明一下:本文里 MLP(Multi-Layer Perceptron,多层感知机)和 FFN(Feed-Forward Network,前馈网络)指的是同一段结构——attention 后面那层负责做位置内加工的网络。叫 MLP,侧重的是它“由多层线性变换加非线性激活组成”这个结构特征;叫 FFN,侧重的是它在 block 里承担“对每个位置独立做一次前馈计算”这个功能角色。在 Transformer 语境里两者基本可以互换。
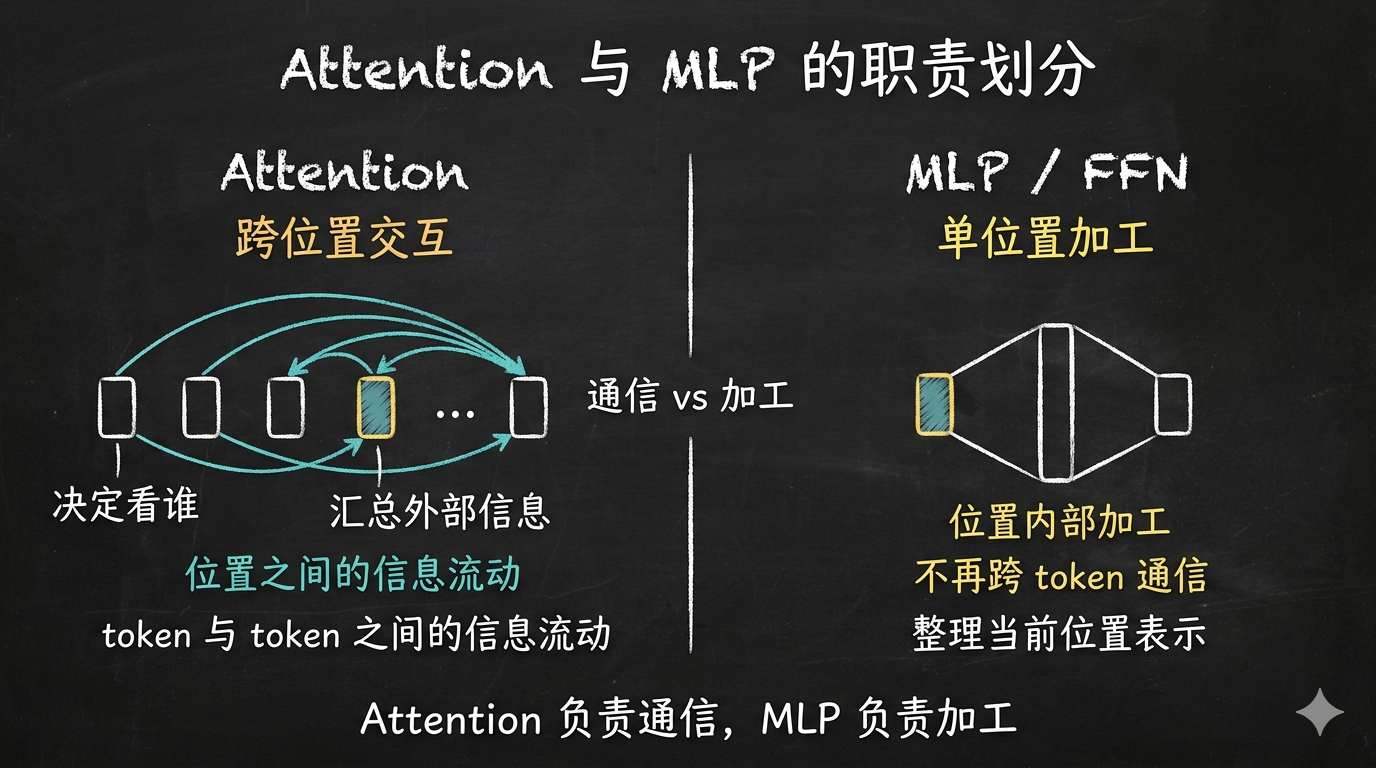
一个 block 里,attention 和 MLP 分别完成哪一步
如果把 attention 看成开会,那么它做的事情很像听别人发言、收集外部信息,决定听谁的、记什么。MLP 更像散会之后回到自己位置,把刚才听到的内容重新整理成自己的判断。
这就是 attention 和 MLP 最核心的分工。attention 负责的是位置和位置之间的信息交互,MLP 负责的是单个位置内部的表示加工。前者处理的是“我该从别人那里拿什么”,后者处理的是“我拿到之后,应该把自己变成什么样”。只有这两步接在一起,一个 token 才能既吸收上下文,又形成新的内部表示,继续传给下一层。
实际的 Transformer block 里,attention 和 MLP 之间还有残差连接(residual connection)和归一化层(如 RMSNorm)。这里先聚焦 attention 和 MLP 的分工,残差和归一化留到后面的文章展开。
看清这层分工之后,下一个问题就是:MLP 内部到底长什么样?最常见的结构其实很简单——两层线性层,中间夹一层激活函数。但为什么需要这层激活函数?如果去掉它,只留两层线性层,会怎样?
MLP 真正关键的,是中间那层激活函数
刚才提到,MLP 最常见的结构就是“两层线性层,中间夹一层激活函数”。外形上看起来很普通,很容易被误解成:这不就是再做两次矩阵乘法吗?
但 MLP 真正重要的地方,恰恰在中间那层激活函数上。
原因很简单:如果没有这层非线性,那么前后一串线性变换其实可以合并成一个更大的线性变换。你前面乘一个矩阵,后面再乘一个矩阵,本质上仍然只是把输入做了一次线性映射。层数虽然看起来变深了,但表达能力并没有因为“多乘了一次”而发生质变。
激活函数的作用,就是在两层线性变换之间插入一个非线性的“关卡”。它会逐个检查上一层输出的每个数值,然后做出不同的处理:有些值被原样放行,有些被压低到接近零,有些在负数区间被直接截断。经过这一步之后,数据的分布被重新塑形了——原本线性变换只能做到的“旋转和缩放”,现在变成了可以弯折、可以选择性屏蔽的更复杂变换。正是这种逐元素的非线性处理,让深层网络的表达能力远超简单的矩阵连乘。
激活函数的影响还不止于前向计算。反向传播时,梯度需要沿着激活函数的导数往回流。如果某个激活函数在一大片区域里导数都很小,梯度在往回传的过程中会越来越弱,前面的参数就收不到足够的更新信号——这就是常说的梯度消失。所以激活函数同时决定了两件事:“这一层怎么加工数据”和“这一层好不好训练”。
放到图上看会更直观。像 ReLU、GELU、SiLU 这些常见激活函数,对同一个输入值的处理方式各不相同:ReLU 会直接把负数截成零,GELU 和 SiLU 在负区间都会保留一部分非零输出,但 SiLU 的负区间凹陷更明显。曲线形状的差异,对应的是完全不同的信息加工策略;而它们的导数形状,则直接影响训练时梯度能否顺畅地往回流。
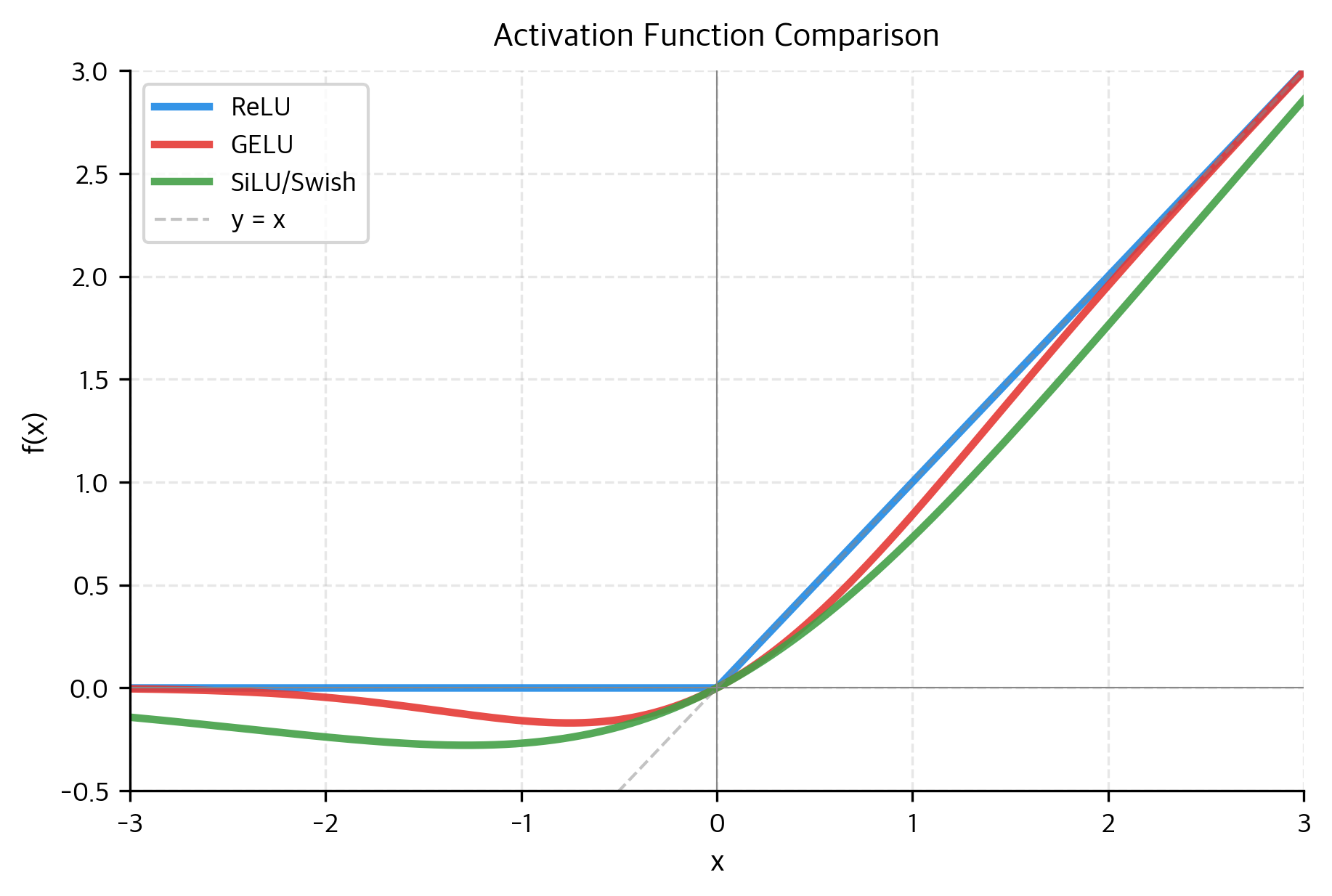
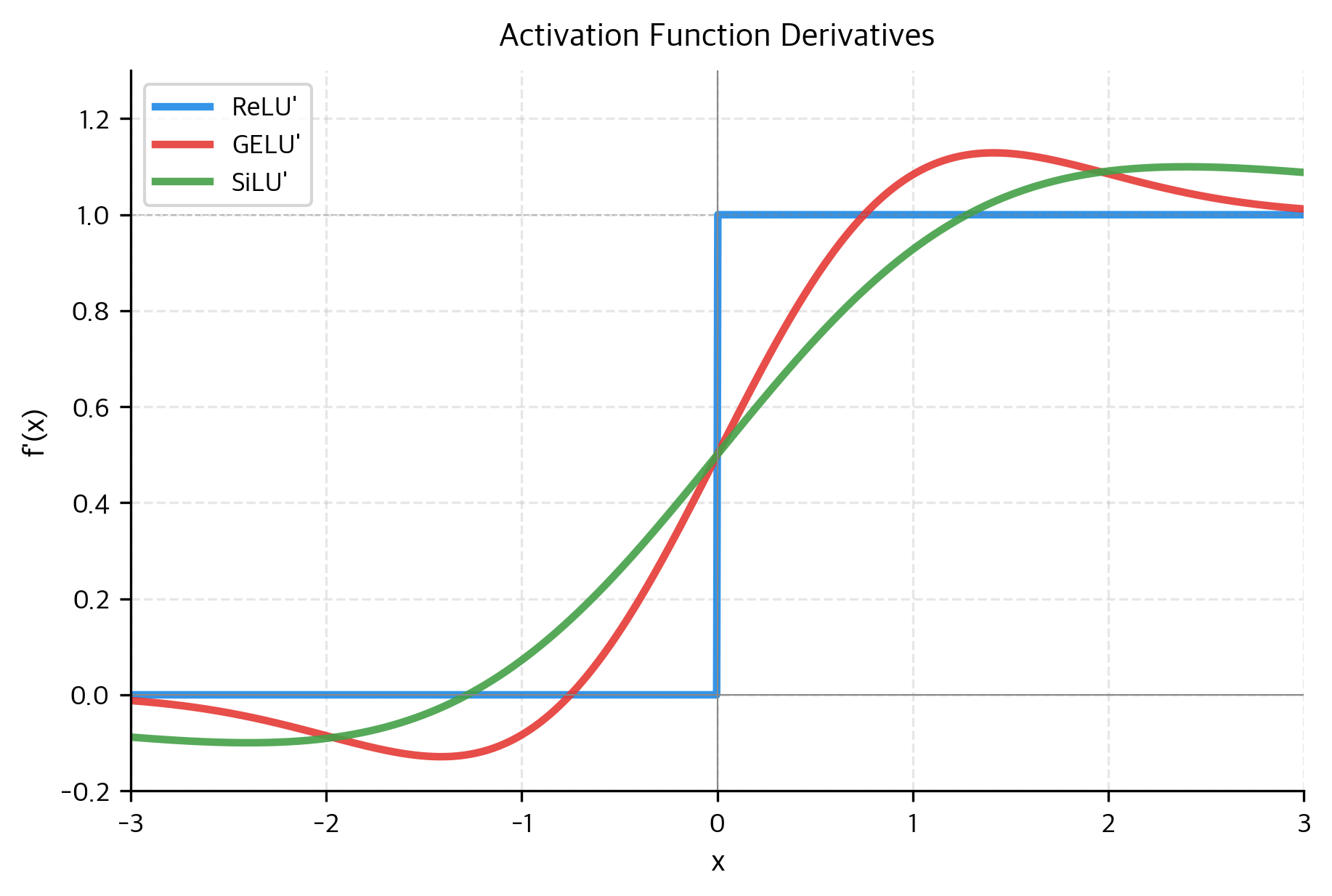
从这个角度看,激活函数才是让 MLP 真正成立的关键,它本身就是 MLP 设计的核心组成部分。 没有它,attention 后面接的就只是一次线性变换的延长;有了它,模型才真的获得了在当前位置内部重新组织表示的能力。后来不同模型在 MLP 上的改动也印证了这一点——大家花精力最多的地方往往是激活函数的选择,并由此进一步发展出 gated FFN、SwiGLU 这类更复杂的非线性结构。
既然 MLP 的关键不是“再乘两次矩阵”,那一个最朴素的 FFN 到底长什么样?
一个最朴素的 FFN 长什么样
在看 MiniMind 的真实代码之前,先把最基本的 FFN 结构理清楚。MiniMind 实际用的是更进阶的 SwiGLU 版本,但要理解它为什么那样写,得先知道最朴素的版本在做什么。
FFN 接到的是 attention 之后的 hidden_states。这时候,每个 token 已经不再只是原来的自己,而是已经混进了一部分上下文信息。但这些信息还只是“收进来了”,还没有被重新组织成更适合下一层继续处理的内部表示。FFN 接手的,就是这一段工作。
最常见的第一步,是先把表示从 hidden_size 投到一个更大的维度,也就是常见的 intermediate_size。升维的目的是给后面的非线性加工留出更大的操作空间——在低维空间里,不同模式的表示可能挤在一起、难以分开;投到高维之后,这些模式更容易被拉开到不同维度上,激活函数才能对它们做更精细的选择性保留或压制。
接下来就是前面讲过的中间那层激活函数。它对每个维度的值做非线性处理——有些放行,有些压低,有些截断——让这一步变换真正超越简单的矩阵连乘。
等这一步非线性加工做完之后,模型还会再把表示从高维空间压回 hidden_size。这一步是把刚才在高维空间里完成的展开、筛选、重组,重新压缩回 block 统一使用的表示维度。下一层 Transformer block 接收的,已经是一份经过内部加工的新 hidden_states。
所以,如果把整个 FFN 用一句话概括,它其实是在做这样一件事:先把 attention 带回来的上下文信息摊开,再通过非线性加工重新组织,最后压缩成下一层还能继续使用的新表示。 这个“升维—激活—降维”的三步结构,刚好对应了表示加工所需要的三个阶段。
看到这里,其实还只是最朴素的 FFN 版本。真正有意思的问题是:如果 MLP 的任务是“加工”,那模型后来为什么还不满足于这种最基本的“升维—激活—降维”,而是进一步走到了 gated FFN、SwiGLU 这种带门控的结构?
从朴素 FFN 到 SwiGLU,模型为什么要加一道门
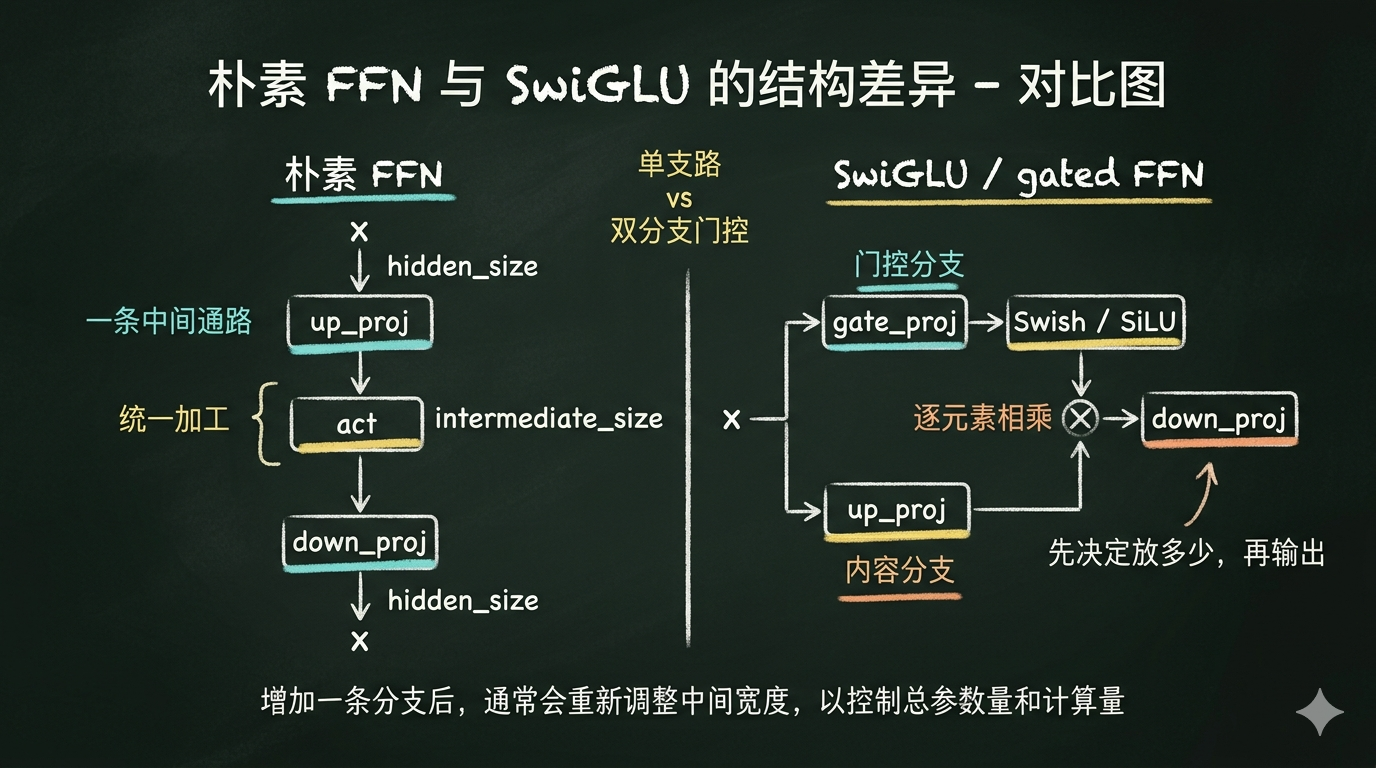
如果把最朴素的 FFN 看成“先摊开、再加工、再压回去”,那它已经能完成 Transformer block 里最基本的位置内加工任务了。一个 token 在 attention 之后带着上下文进来,经过一轮非线性变换,再输出成新的 hidden_states,这套流程本身没有问题,早期 Transformer 也就是这么做的。
但模型继续发展之后,大家慢慢发现,光靠一条统一的变换路径还不够细。因为“加工”这件事本身,可能并不是一个单一步骤。一个更自然的拆法是:先生成候选内容,再决定这些内容该放行多少。换句话说,除了“把输入变成什么”,模型还想显式控制“哪些部分值得真正通过”。
这就是 gated FFN 背后的直觉。和朴素 FFN 相比,它不再只走一条线,而是把中间过程拆成两路:一路负责生成内容,一路负责产生门控信号。最后再把两路结果做逐元素相乘(element-wise multiply),让门控那一路去控制内容那一路有多少能够通过。所谓逐元素相乘,就是把两个同形状张量对应位置的数字一一相乘——门控值接近 0,对应内容就被压住;接近 1,内容就被放行。这和矩阵乘法不同,它不做行列组合,只在每个位置上独立决定“放多少过去”。
这样一来,表示加工不再只有“变换”这一层含义,而开始兼有“选择”这层含义。朴素 FFN 对所有内容做统一加工;gated FFN 则是在加工的同时多了一道阀门,让模型可以对不同维度做更细粒度的筛选和放行。
SwiGLU 就是在这条路上比较典型的一种实现。它的名字可以拆开理解:后半截 GLU 是 Gated Linear Unit,意思是带门控的线性单元;前半截 Swi 指的是这里用到的激活函数是 Swish,也就是现在很多实现里常见的 SiLU(Swish 和 SiLU 是同一个函数的两种叫法,后文统一用 SiLU)。把这两个部分合起来,SwiGLU 本质上就是:用 Swish/SiLU 这类更平滑的激活函数去做门控,再和内容分支相乘。
如果只看函数形状,Swish 和 ReLU 最大的差别就在于:它不会把负数一刀切成 0,而是会更平滑地保留一部分信息。这种平滑性放到门控结构里,会让“放多少内容通过”这件事不那么生硬。
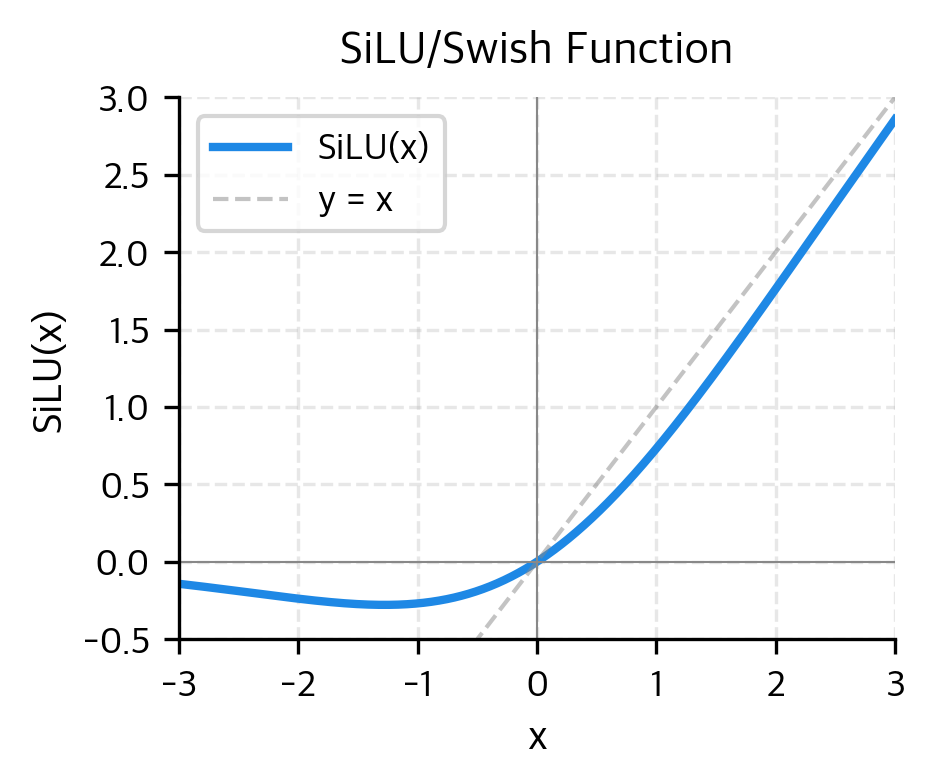
这也是为什么很多现代大模型实现里,用的都不再是最朴素的 FFN,而是各种 GLU 变体。背后的设计意图很明确:位置内加工不该只是一次统一改写,还应该允许模型对不同内容做更细的通过控制。
顺着这个思路,另一个常见问题也就比较好理解了:为什么 gated FFN 里经常会看到 8/3 * hidden_size 这样的中间维度,而不是传统的 4 * hidden_size?
朴素 FFN 只有一条路,常见写法是把维度从 hidden_size 扩到 4 * hidden_size 再压回来。但 gated FFN 变成了内容分支 + 门控分支两路一起算。如果每一路还开到 4 * hidden_size 那么宽,整个模块的参数量就会翻倍。所以需要把每条分支适当收窄,让总成本控制在和传统 FFN 接近的范围里。
用具体数字来看会更清楚。朴素 FFN 只有两层线性层,每层线性层本质上就是一个矩阵:
- 第一层把
hidden_size(记作h)升维到4h,对应一个h × 4h的矩阵,参数量是4h² - 第二层把
4h压回h,对应一个4h × h的矩阵,参数量也是4h²
两层加起来总参数量约 8h²(这里按不带 bias 计算)。
换成 gated FFN 之后有三层投影,每层同样是一个矩阵:
gate_proj:h -> m,生成门控信号,参数量hmup_proj:h -> m,生成内容分支,参数量hmdown_proj:m -> h,压回原始维度,参数量mh
三层总参数量约 3hm。如果想让 gated FFN 的总参数量和经典 4h FFN 保持在同一量级,就要让 3hm ≈ 8h²,解出来就是 m ≈ 8/3 h。所以这里的 8/3 并没有什么理论上的特殊含义,它就是一个工程上的平衡点:门控结构多了一条分支,为了不让总参数量膨胀,把每条分支的宽度从 4h 收窄到了 8/3 h。
从朴素 FFN 走到 gated FFN,再到 SwiGLU,背后其实是一条很一致的演化路线:模型越来越不满足于“统一加工”这件事,而是开始把“生成什么内容”和“让多少内容通过”拆开处理。attention 之后的信息不只是被重新写一遍,而是被更精细地筛选、控制和重组。
如果这时候再回到 MiniMind 的真实实现里看,前面讲的“门控分支 + 内容分支 + 下投影”其实就是 model/model_minimind.py 里 FeedForward 这段代码:
class FeedForward(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
if config.intermediate_size is None:
intermediate_size = int(config.hidden_size * 8 / 3)
config.intermediate_size = 64 * ((intermediate_size + 64 - 1) // 64)
self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.dropout = nn.Dropout(config.dropout)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
return self.dropout(self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x)))代码里有一行 64 * ((intermediate_size + 64 - 1) // 64),作用是把中间维度向上取整到 64 的倍数,方便 GPU 硬件做更高效的并行计算,属于工程优化,不影响模型逻辑。
再看 forward 方法,逻辑就会顺很多:gate_proj(x) 这一路先经过激活函数 act_fn,产生门控信号;up_proj(x) 这一路直接做线性变换,生成内容分支。注意激活函数只作用在 gate_proj 那一路上——正是因为这一路的输出充当门控信号,需要通过非线性来决定“放多少过去”,而内容分支本身不需要再过一次激活。两路逐元素相乘之后,再交给 down_proj 压回 hidden_size。
代码里的 ACT2FN 本质上就是一个字典,键是字符串(如 'silu'),值是对应的激活函数实现。ACT2FN[config.hidden_act] 做的事情就是根据配置找到要用的激活函数。前面讲过的 SwiGLU、8/3 * hidden_size,也都不是额外补进去的概念,而是这段真实实现里本来就在发生的事情。
回到主线上来。FFN 里的投影矩阵(gate_proj、up_proj、down_proj)都属于模型参数——它们不是写死的规则,而是在训练过程中一点点学出来的。训练做的事情,就是不断调整 attention 和 MLP 里的这些参数,让整条加工链路越来越会做对任务。
当所有 token 共用同一套 MLP,问题就开始出现了
走到这里,一个 Transformer block 里 attention + MLP 的基本闭环已经清楚了:先从上下文取回信息,再在当前位置内部加工成新的表示。
这套结构已经很强了,事实也证明它足以支撑 Transformer 走到非常远的地方。但它也留下了一个值得追问的问题:不同 token,真的都应该经过同一种加工方式吗?
表面上看,attention 之后每个 token 都会进入同一层 MLP。这意味着,不管当前这个 token 是一个普通词、一个专有名词、一段代码里的符号,还是一个需要更强逻辑组合的信息单元,它们进入的都是同一套前馈网络,用的是同一组参数,接受的是同一种加工流程。attention 那一段已经根据上下文做了“看谁、记什么”的动态选择,但到了 MLP 这里,后续加工却重新回到了“一套统一车间处理所有输入”的模式。
这套统一处理方式当然不是错的。恰恰相反,它足够简单、足够稳定,也足够强,才成为了标准 Transformer block 的一部分。但问题在于,模型越大、任务越复杂、输入分布越丰富,这种“所有 token 共用同一套加工器”的方式就会越来越力不从心。因为不同类型的信息,未必需要同一种后续加工路径。有些 token 更需要事实补全,有些更需要语义压缩,有些更需要逻辑改写;如果它们都被送进同一套 MLP,模型只能把所有这些加工需求都压进同一组参数里,最终每种需求都只能得到一个折中的处理。
既然 attention 已经会决定该看谁,为什么后面的加工还要让所有 token 共用同一套参数?
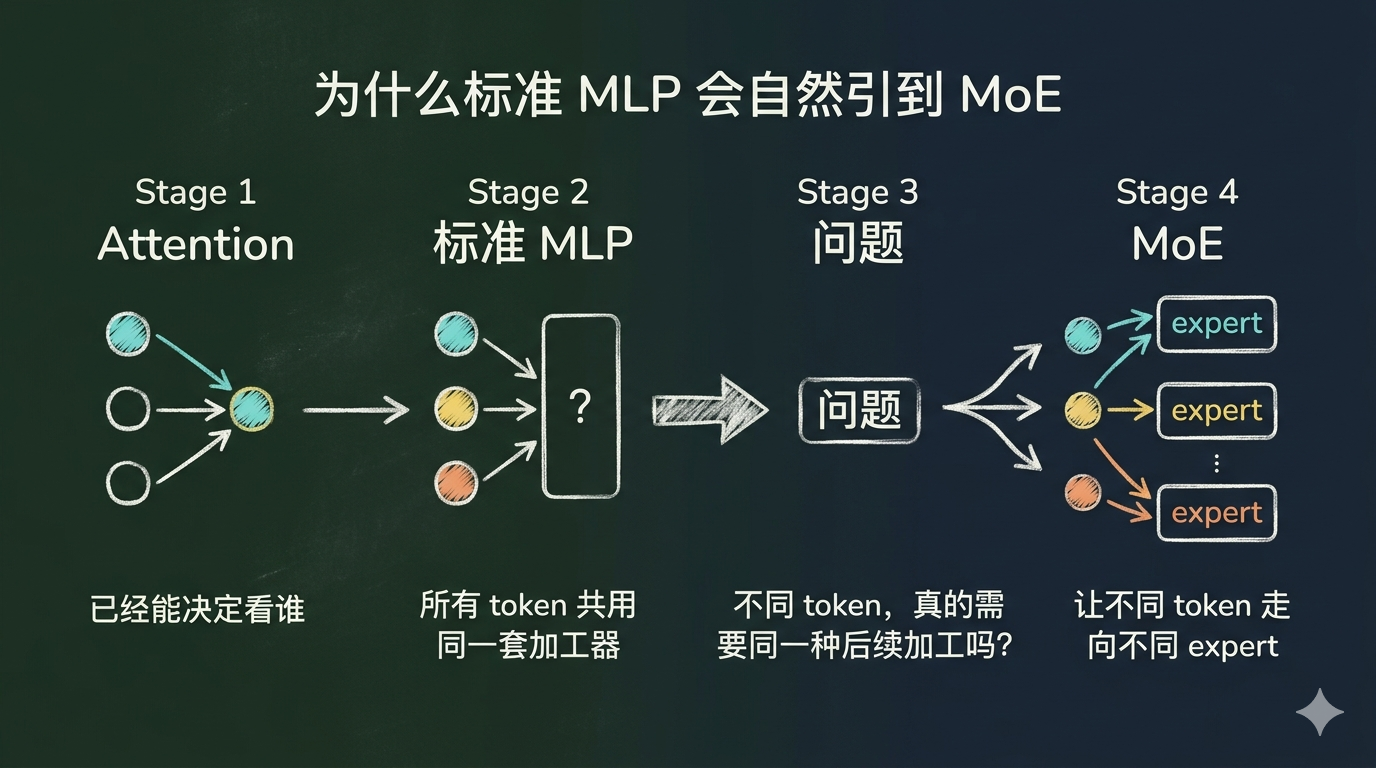
这就是 MoE(Mixture of Experts) 想解决的问题。它不是把 attention 换掉,而是继续追问 MLP 这一段:如果不同 token 需要的后续加工并不一样,能不能让它们在进入前馈网络时,也走向不同的专家路径?大致思路是:准备多套 FFN“专家”,再用一个 router 来决定每个 token 应该去哪几个专家。
这样回头看,MoE 就不是突然冒出来的新模块,而是顺着标准 Transformer block 自然长出来的下一步。下一篇会展开 MoE 的具体结构和设计逻辑。