从 minimind 出发:Attention 是在做什么
上一篇顺了一遍 LLM 训练最小闭环:
再往下读,很快就会碰到下一个问题:一个 Transformer block 里最核心的 attention,到底在做什么?
attention 这个词并不新。很多人都听过《Attention Is All You Need》,也听过 Q / K / V、多头注意力、KV cache、GQA。但这些词放回同一段代码之后,彼此之间的关系往往又变得不清楚了——为什么这里要先有 Q / K / V,为什么后面又会出现多头、mask、KV cache,这些设计分别在解决什么问题?
顺着 MiniMind 的 Attention.forward() 往下读,我们把这条链理清楚。
Attention 要解决什么问题
模型处理文本时,真正面对的不是“句子”这个整体,而是一串 token。这里的 token,可以先理解成模型处理文本时的基本单位。它有时像一个词,有时像一个字,也可能只是词的一部分。总之,它是 tokenizer 切分之后,模型真正拿来计算的单元。
只是,一个 token 想要被正确理解,往往不能只看自己。
比如这句话:
小明把书放回桌子上,因为他已经看完了。
这里的“他”指的是谁?如果只看“他”这个位置本身,其实判断不出来。只有把前面的“小明”和“书”一起纳入上下文,模型才有机会知道,这里的“他”指的是“小明”,而不是“书”。
再比如一句更简单的话:
今天很冷,所以我穿了外套。
如果只看“所以”后面的局部片段,“穿了外套”只是一个动作;把前面的“今天很冷”接进来,这个动作的原因才会变得清楚。
这就是 attention 要解决的核心问题:
让当前位置的表示,不再只来自它自己,而是能够根据需要,从整段上下文里取回信息。
这件事再拆开,其实就是三个更具体的问题:
- 当前位置应该关注上下文里的哪些位置
- 每个位置应该分到多少注意力
- 被关注的位置,最终要把什么信息传回来
后面会出现的 Q / K / V,以及 Q @ K^T -> softmax -> @V,本质上都是围绕这三件事搭起来的。
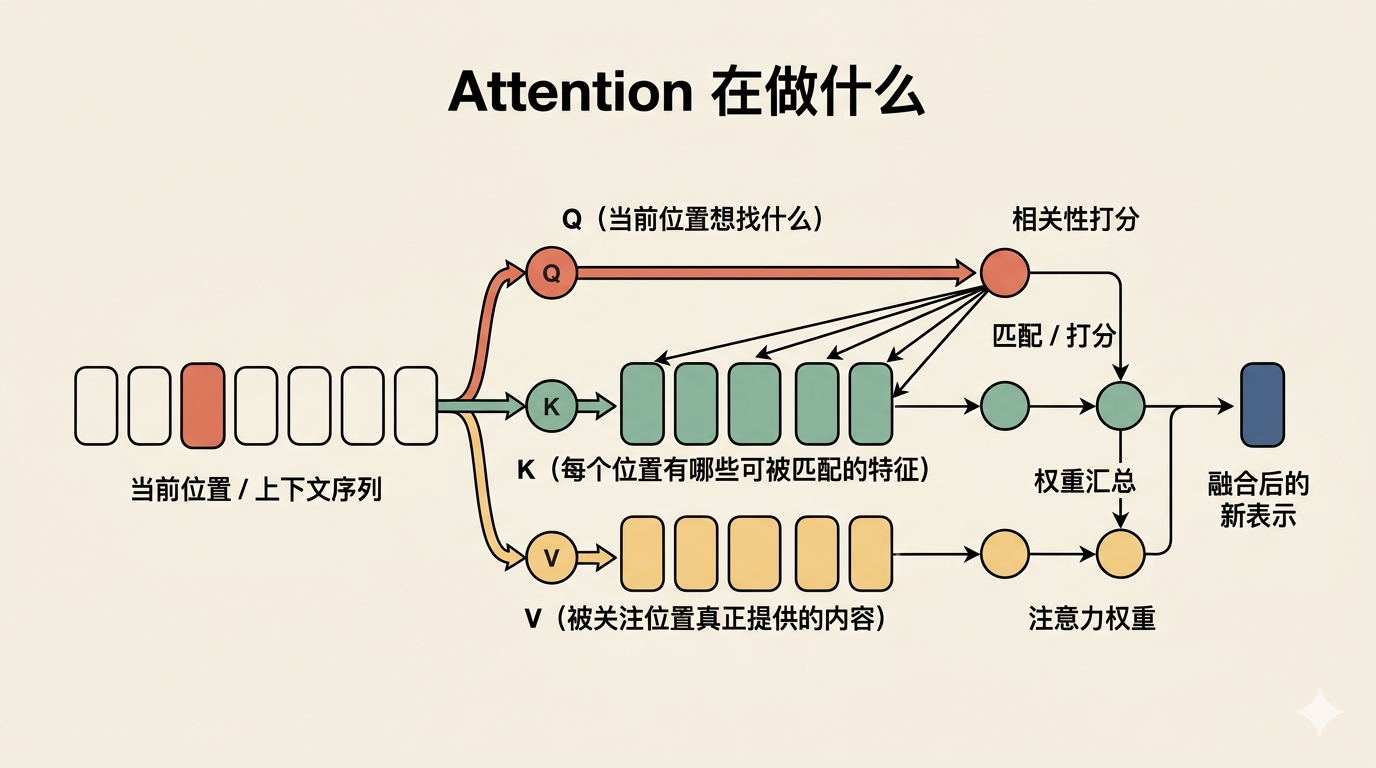
要从上下文里取信息,attention 需要先把输入拆成三种表示
在 MiniMind 的源码里,attention 一开始会做这件事:
xq, xk, xv = self.q_proj(x), self.k_proj(x), self.v_proj(x)这里的输入 x,本质上是上一层传下来的 hidden_states。hidden states 可以理解成模型内部流动的向量表示。前一篇里讲过,input_ids 还是 token 的编号;经过 embedding 和 block 之后,模型真正处理的已经是一串向量,这些向量通常就叫 hidden_states。
同一个输入,为什么要分成三份?因为“从上下文里取信息”这件事,本来就包含三个不同的方面,落到 attention 里,就是:
- Q / Query:当前位置现在想找什么信息
- K / Key:每个位置身上有哪些可被匹配的特征
- V / Value:如果这个位置被关注,它真正能提供什么内容
如果想用一个更直观的类比,可以把 attention 想成一次检索。
- Q 像查询条件
- K 像每条资料的标签
- V 像资料正文
当前位置先带着自己的查询条件 Q,去整段序列里匹配 K,找到值得关注的位置;然后再把这些位置对应的 V 取回来,形成自己的新表示。
从这个角度看,Q / K / V 不是额外叠出来的概念,而是 attention 为了完成“取回上下文信息”这件事,必须做的功能拆分。
一套注意力还不够,所以模型会把它拆成多个 head
到这里,attention 的基本轮廓已经出来了:当前位置拿着 Q 去匹配整段上下文里的 K,再把对应位置的 V 取回来。
接下来的问题是:既然已经能取信息了,为什么还要多头?
原因很简单。上下文关系不止一种。
有些关系很近,比如局部搭配;有些关系很远,比如长距离指代;有些关系更偏语义,有些关系更偏结构。如果所有关系都只靠同一套 Q / K / V 去处理,模型就只能用一种固定视角看上下文,表达能力会受到限制。
所以多头注意力,也就是 multi-head attention,本质上是在做一件事:
把“如何看上下文”这件事拆成多个并行视角,让模型可以同时从不同角度理解同一段序列。
head 就是一种独立的注意力视角。
这也是为什么会有下面这个关系:
hidden_size = num_heads * head_dim这里:
- hidden_size:每个 token 在模型主干里的向量长度
- head_dim:每个 attention head 分到的那部分向量长度
比如在 MiniMind 这类实现里,如果:
hidden_size = 512
num_heads = 8那每个 head 分到的维度就是:
head_dim = 512 / 8 = 64换句话说,一个 token 原本那条 512 维的大向量,不是让每个 head 都完整用一遍,而是拆成 8 份,每份 64 维,让 8 个 head 并行地做 attention。
多头还有一个衍生问题:Q / K / V 各自分配多少头?这个问题放到多头的变体一节展开,有了 KV cache 的背景之后会更容易理解。
从 shape 的变化追踪 attention 的逻辑
读 attention 代码时,很多人不是卡在概念本身,而是卡在 shape 上。因为一旦张量维度跟丢,后面的矩阵乘法、mask 和 cache 都会很难看清。
这里的 shape,就是张量的形状,也就是“这个数据有几维、每一维多长”。
所以这部分最适合顺着 shape 往下看。
attention 的输入是什么形状
进入 attention 的输入 x,通常是上一层传下来的 hidden_states:
x.shape = [bsz, seq_len, hidden_size]这里:
bsz表示 batch size,也就是这一批里有多少条样本seq_len表示 sequence length,也就是每条样本里有多少个 tokenhidden_size表示每个 token 当前表示向量的长度
比如:
[2, 5, 512]表示:这一批有 2 条样本,每条样本长度是 5 个 token,每个 token 现在都用 512 维向量表示。
attention 先做的,不是计算分数,而是把大向量拆成多头结构
源码里接下来会先做两类事情:
第一步,是把输入分别映射成 Q / K / V:
xq, xk, xv = self.q_proj(x), self.k_proj(x), self.v_proj(x)第二步,是把这些大向量重新拆成多头结构:
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)这里的 view(...) 是 PyTorch 里的一个高频操作,相当于 reshape——重新解释张量的形状,而不是改动数据本身。
这一段的核心动作,其实可以压成一句话:
attention 会先把原本一条大向量,拆成多个 head 对应的小向量。
如果暂时不考虑 GQA,最直观的变化是这样的:
- 原来每个 token 是一条
hidden_size维的大向量 - 现在会被拆成
num_heads × head_dim
从:
[bsz, seq_len, 512]
拆成:
[bsz, seq_len, 8, 64]
在 MiniMind 里,因为用了 GQA,Q 和 K / V 的头数不完全一样,所以会看到:
Q: [bsz, seq_len, n_heads, head_dim]K / V: [bsz, seq_len, n_kv_heads, head_dim]
但不管是标准多头还是 GQA,这里的逻辑都一样:先把大向量拆成多头结构。
为什么后面还要把维度顺序再调一次
接下来源码里还会做一步:
xq = xq.transpose(1, 2)把:
[bsz, seq_len, heads, head_dim]
变成:
[bsz, heads, seq_len, head_dim]
transpose 的作用是交换维度位置。
这一刻先不用急着进矩阵乘法,只要先记住一点:attention 之所以要做这次维度调整,是因为后面真正计算相关性时,更方便按“每个 batch、每个 head”分别处理整段序列。
这一步是在给后面的 Q @ K^T 铺路。
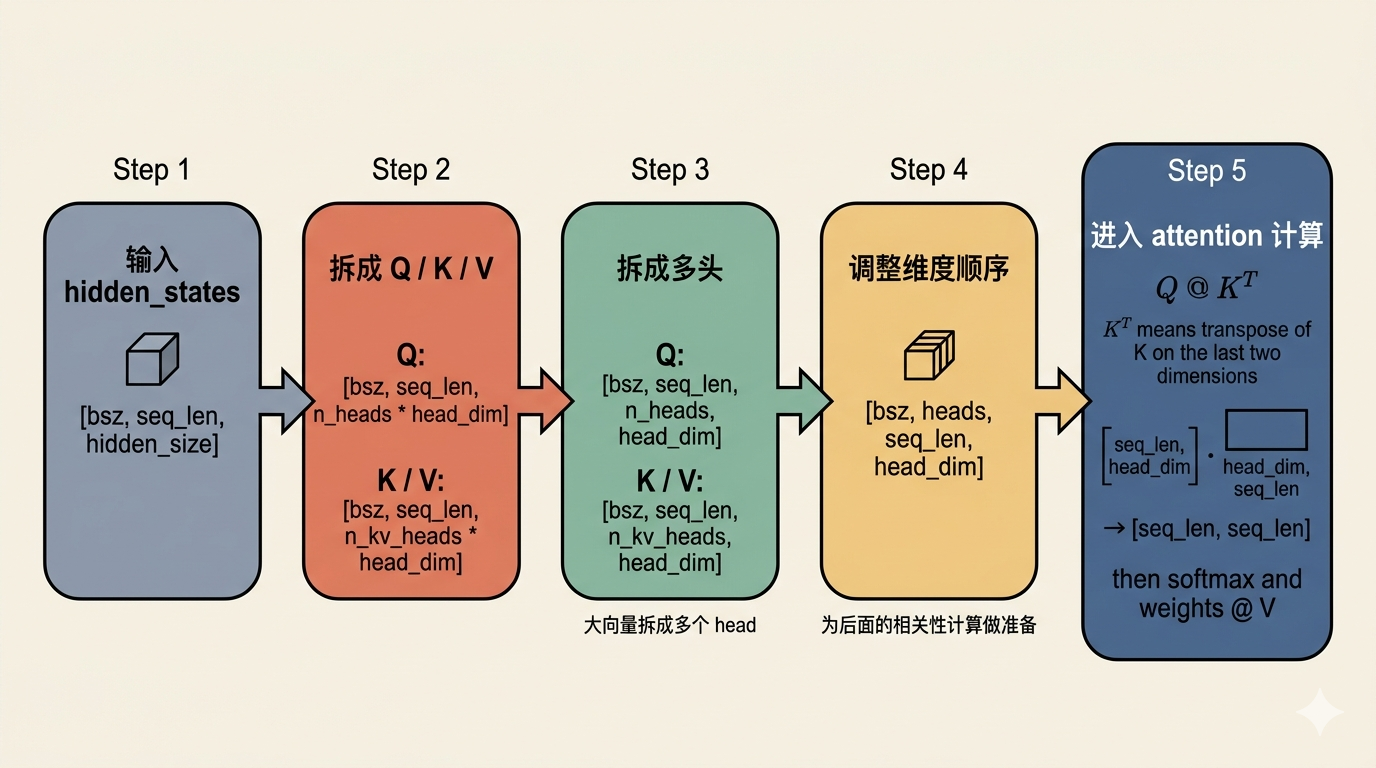
Attention 为什么真的能融合上下文
attention 最核心的三步,可以先写成这条链:
scores = Q @ K^T / sqrt(head_dim)
weights = softmax(scores)
output = weights @ V除以 sqrt(head_dim) 是为了防止点积值随维度增大变得过大,进而让 softmax 进入梯度极小的饱和区。
这三步里,真正让上下文进入当前位置的,是最后一步;但要看清最后一步,前两步也得顺着理解。
第一步:先把“整段上下文里该看谁”算出来
有了前面的维度调整之后,Q 和 K 的形状会更适合后面的计算:
Q: [bsz, heads, seq_len, head_dim]K: [bsz, heads, seq_len, head_dim]
这里有一个最关键的 PyTorch 规则:高维张量做 @ 运算时,前面的维度可以看成批处理维,最后两维才是真正参与矩阵乘法的维度。
这里的 @ 就是矩阵乘法。K^T 里的 T 表示 转置(transpose),也就是把 K 最后两维的位置交换过来:原本是 [seq_len, head_dim],转置之后就变成 [head_dim, seq_len]。
所以当代码写成:
Q @ K^T
本质上发生的事情是:
- 对每个 batch
- 对每个 head
- 都单独拿出一块
Q: [seq_len, head_dim] - 再和一块
K^T: [head_dim, seq_len]去做矩阵乘法
结果就会变成:
[seq_len, seq_len]
在每个 head 里,都会得到一张“整段序列里,每个位置对每个位置的相关性分数表”。
为什么这个乘法算的是相关性?因为这张表里的每个位置,本质上都对应“某个 query 向量”和“某个 key 向量”之间的一次点积。两个向量越对得上,分数通常就越高;越对不上,分数通常就越低。于是这一步就把“当前位置和上下文里哪些位置更相关”算了出来。
如果把这张表想象成一个二维表格:
- 行表示当前是谁在发出查询
- 列表示当前去匹配谁
那么 Q @ K^T 这一步做的事是:
让当前位置先对整段上下文做一遍相关性打分。
这一步已经回答了“该看谁”这个问题,但还没有真正把内容拿回来。
第二步:把相关性分数变成注意力权重
打分还不够,模型还需要知道:这些位置分别该分到多少注意力。
这就是 softmax 的作用。
softmax 是一种“把原始分数变成权重分布”的操作:把一组分数变成一组非负权重,这些权重加起来等于 1。
在前面那张 seq_len × seq_len 的分数表里,最后一维表示的是:当前这个位置,对整段上下文里所有位置的分数列表。
所以当 softmax 沿最后一维计算时,它做的事情其实很直接:把“当前这个位置对所有位置的原始分数”,变成“当前这个位置对所有位置的注意力分配”。
对某个 query 位置来说,softmax 之后得到的是:
- 这个位置更该看谁
- 每个位置分到多少注意力
- 哪些位置几乎不看
到这一步,attention 已经从“相关性打分”变成了“注意力分配”。
第三步:真正把上下文混进来的,是 weights @ V
真正关键的地方在这里。
前面 softmax 之后,模型已经知道每个位置该把注意力分给谁;但“知道该看谁”还不等于“已经拿回了内容”。
真正把上下文带回来的,是最后这一步:
weights @ V
具体来说:
- 对于当前位置
- 拿它刚刚得到的那一行注意力权重
- 去对整段序列里所有位置的 V 做一次加权求和
所以当前位置最后拿到的新表示,不再只是它自己原来的向量,而是:
整段序列所有位置的 V,按照当前位置注意力权重做加权汇总之后的结果。
如果只看一个很小的例子,这件事会更直观。
比如某个位置先通过 Q @ K^T + softmax,得到对三个位置的注意力权重:
[0.1, 0.7, 0.2]
那它最后拿到的新表示就会是:
0.1 * v1 + 0.7 * v2 + 0.2 * v3
这就是为什么 attention 真的是在“融合上下文”,而不是只算了一张分数表。
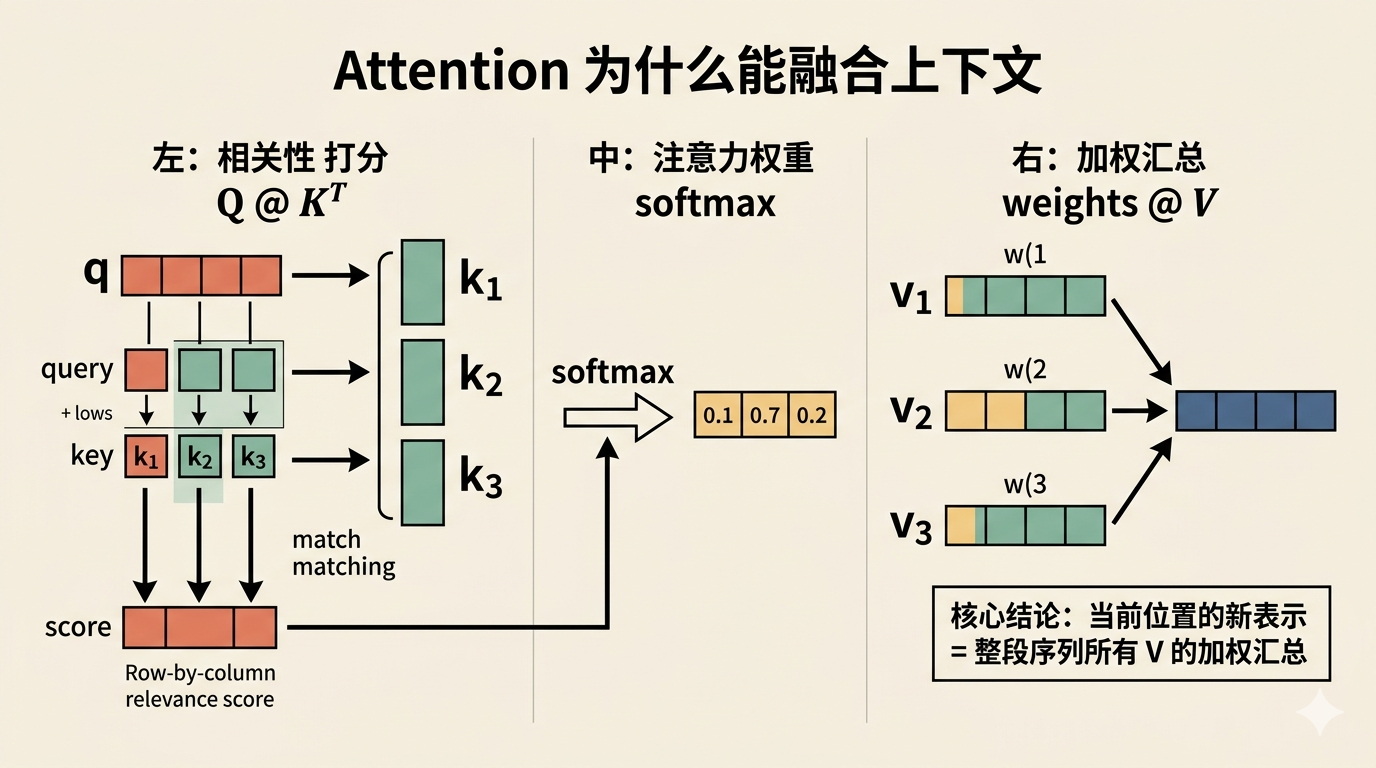
这三步可以压成一句话:
Q @ K^T决定看谁softmax决定看多少@V真正把别处的信息混进来
为什么还需要 mask
attention 已经能“对整段上下文打分,再取回信息”了,但这里还缺一个约束:并不是所有位置都应该被随便看见。
不能看未来,所以需要 causal mask
语言模型训练时做的是 next-token prediction。
这意味着当前位置在预测时,只能看自己和前面的 token,不能看未来。否则就相当于答案已经偷看到了。
causal 是“因果的、自回归的”意思;mask 是一种屏蔽规则。
所以 causal mask 的作用就是:
把未来位置屏蔽掉。
源码里常见做法是把未来那些位置对应的分数加上 -inf 或一个非常大的负数。这样 softmax 之后,这些位置的权重就会变成 0。
换句话说,这些位置并没有从张量里消失,但在注意力分配时拿不到任何权重。
不能看 padding / 无效位置,所以还需要 attention_mask
除了“不能看未来”,还有一种限制来自输入本身。
在实际训练里,一个 batch 里的样本长度常常不一样,所以会补 padding。padding 就是为了把不同长度样本凑成统一形状而补出来的位置。
这些位置不是真正的文本内容,也不应该参与 attention,所以还需要 attention_mask。
它和 causal mask 的区别可以简单记成:
- causal mask:限制时间方向,不能看未来
- attention_mask:限制输入有效性,不能看 padding 或无效位置
为什么生成时还需要 KV cache
到这里 attention 的基本机制已经有了。但如果进入推理场景,还会出现另一个现实问题:每生成一个新 token,难道都要把前面整段序列重新算一遍吗?
如果真的每次都从头算,成本会很高。
所以推理时通常会引入 KV cache。
这里:
- cache:缓存,也就是把后面还会反复用到的结果先存起来
- KV cache:把历史位置已经算好的 K 和 V 先缓存起来,下次生成新 token 时直接复用
KV cache 里为什么缓存 K / V,而不缓存 Q
这个地方容易绕住,因为直觉上会觉得:既然前面每个位置也都算过 query,那为什么旧的 Q 不一起缓存?
关键在于,旧位置的 Q 只在“它当时那一步”有用。
可以这样理解:
- 当第 5 个位置在计算时,它会发出属于自己那个位置的 Q,用来决定“我该看前面哪些位置”
- 等模型继续往后生成、第 6 个位置开始计算时,真正需要的是“第 6 个位置自己的 Q”
- 第 5 个位置当时发出的 Q,并不会再被第 6 个位置直接拿来用
换句话说,Q 代表的是“当前位置这一刻发出的查询”。位置变了,查询也就变了,所以每一步都要重新生成新的 Q。
K / V 不一样。历史位置一旦存在,它们提供出来的匹配特征和内容表示,后面每一个新位置都还可能继续用到。
所以在生成阶段:
- Q 是一步一换的临时查询
- K / V 是历史位置留下来的可复用内容
真正值得缓存的,是后者。
沿序列维拼接 KV cache
在拼 cache 之前,K / V 的形状大致是:
[bsz, seq_len, kv_heads, head_dim]
当前又生成了新 token 之后,最自然的事情就是把:
- 历史序列里已经缓存的 K / V
- 当前新位置算出来的 K / V
接到一起。
拼接发生在序列长度那一维,所以 cache 变长,表示的不是 head 数变了,也不是向量维度变了,而是:可被检索的上下文序列变长了。
多头的变体:MHA、GQA 和 repeat_kv
有了 KV cache 的背景,前面留下的问题就可以展开了:Q / K / V 各自分配多少头?
这里有三种常见设计,区别不在于 attention 的目标,而在于 K / V 头数的分配方式:
- MHA(Multi-Head Attention):Q 有多少头,K / V 也有多少头,每个 Q head 都有自己独立的 K / V head。
- GQA(Grouped-Query Attention):Q 头仍然很多,但 K / V 头更少,多个 Q heads 共享一组 K / V。
- MQA(Multi-Query Attention):更进一步,很多 Q heads 共享同一组 K / V。
推理时缓存的正是 K / V,所以 K / V 头越多,缓存越大,推理开销越高。MHA 表达自由度最高,但推理成本也最高;GQA 是效果和效率之间的折中;MQA 更省,但约束也更强。
GQA 的做法是:保留较多的 Q heads,维持多视角查询;同时减少独立 K / V heads,让缓存和推理成本降下来。
减少 K / V 头,会不会让信息变少
确实会有一些约束,这也是 GQA 本来就做出的折中。最直观的区别是:
- 在标准 MHA 里,每个 Q head 都有自己独立的一套 K / V,可以学到更自由的匹配和取值方式
- 到了 GQA 里,多个 Q heads 会共享同一组 K / V,独立性没有那么强
所以从表达自由度上说,GQA 通常比 MHA 更受约束一些。换句话说,它确实不是毫无代价地“白赚”效率。
但工程上大家仍然愿意用它,是因为这个代价通常不大,而换来的推理收益却很实在:KV cache 更小,读写更省,长上下文生成时压力也更低。
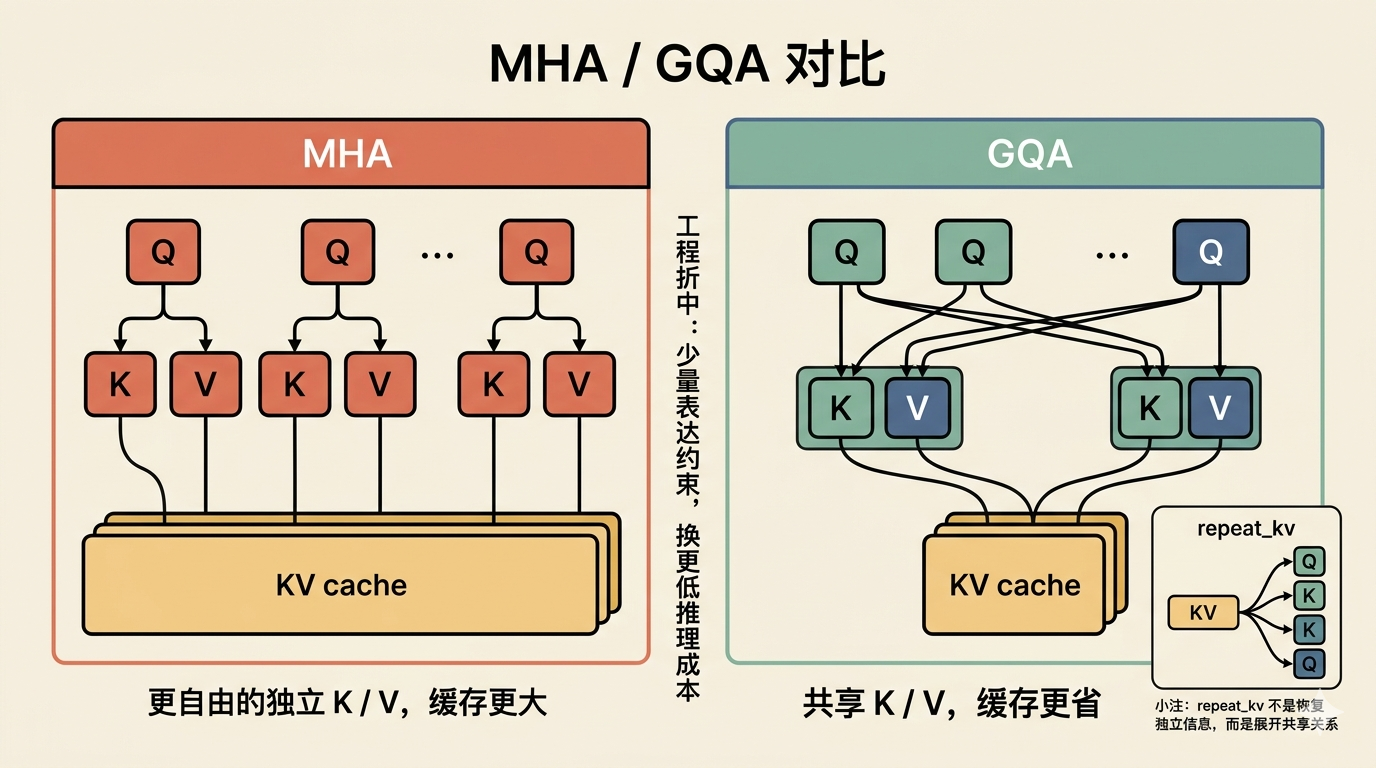
repeat_kv 的作用是什么
理解这一步,关键是先抓住一点:前面减少的是“独立的 K / V 头数”,不是说后面计算时就不需要和 Q head 对齐。
attention 真正计算时,Q 还是要按 head 去和对应的 K / V 配合。但在 GQA 里,K / V 头本来更少,所以后面要做的不是“重新生成新的 K / V”,而是把原本那几组共享的 K / V,按计算需要展开给多个 Q heads 使用。
这就是 repeat_kv 在做的事。
所以 repeat_kv 不是“把丢掉的信息恢复回来”,也不是“重新造出新的独立 K / V 头”,而只是把共享关系展开成便于后续 attention 计算的形状。
为什么最后还要把多头结果拼回 hidden_size
经过 attention 核心计算之后,输出的形状大致还是:
[bsz, heads, seq_len, head_dim]
这说明 attention 内部仍然处在“多头格式”里。
但 Transformer block 的主干前后接口不是这种格式,它更统一地使用:
[bsz, seq_len, hidden_size]
所以 attention 最后还要做一轮 shape 收束:
- 先把维度顺序从
[bsz, heads, seq_len, head_dim]调回[bsz, seq_len, heads, head_dim] - 再把多个 head 拼接回一条大向量,也就是
[bsz, seq_len, hidden_size] - 最后再经过
o_proj,把这条拼接后的向量映射回 block 主干继续使用的表示空间
对应到代码,大致就是:
output = output.transpose(1, 2).reshape(bsz, seq_len, -1)
output = self.o_proj(output)拼接之后 shape 已经是 [bsz, seq_len, hidden_size],但这只是把各个 head 的结果直接并排,不同 head 之间没有交互。o_proj 是一个线性层,让模型可以学习如何跨 head 混合信息,把并排的各头输出投影成真正可用的统一表示。
所以 attention 的内部计算虽然拆成了很多 head,但它交回给 block 的,最终还是一条统一的 hidden_size 向量表示。只有这样,它后面才能继续接 residual、MLP 和下一层 block。
回头看 Attention.forward()
现在再回头看 Attention.forward(),你看到的就不再是零散的 Q / K / V、mask、KV cache,而是一条围绕同一个目标组织起来的链:
让当前位置根据需要,从整段上下文里取回信息,并把这些信息融合成自己的新表示。
顺着这个目标看,整段逻辑其实很清楚:
- 先把输入拆成 Q / K / V,分别承担查询、匹配和取值的功能
- 再把表示拆成多个 head,让模型能从不同视角并行处理上下文
- 接着通过
Q @ K^T算出该看谁,通过 softmax 算出看多少,再通过@V真正把上下文融合进来 - 同时用 mask 保证模型不会看见不该看的位置
- GQA 通过减少 KV 头数降低模型参数量和 cache 体积;KV cache 在推理阶段避免重复计算
- 最后把多头结果重新收回到统一的
hidden_size里,交回 block 主干继续往后走
下一篇解读 MLP 到底在做什么,为什么 attention 之后还需要再来一段前馈网络。