从 minimind 出发:LLM 训练代码最小闭环到底在做什么
真的去看一个 LLM 项目的训练代码,到底该怎么看?
MiniMind 是一个从零用 PyTorch 实现的大语言模型训练项目,模型最小只有 26M 参数,却覆盖了 Pretraining、SFT、DPO 等完整训练流程。因为代码量小、结构清晰,在 GitHub 上获得了 40k+ Star,成了很多人入门 LLM 训练的第一个项目。
读它的代码时,卡住人的地方往往很微妙——tokenize、input_ids、embedding、hidden_states、lm_head、logits、labels、cross_entropy、loss、optimizer……这些词单独看好像都认识,但放在一起就连不成一条线:谁先谁后,分别在干什么,数据又是怎么一步步流过去的?
与其急着深挖 Transformer 的数学细节,不如先做一件更基础的事:把训练代码里的最小闭环先串起来。
这个系列从读 MiniMind 代码出发,不逐行解释实现,而是把这些最容易散掉的概念重新串起来。本文先覆盖两个问题:Pretraining/SFT/DPO 分别在训练什么、以及数据在模型里是怎么跑的。搞明白这两条线,再去看具体代码,心里就大概有底了。
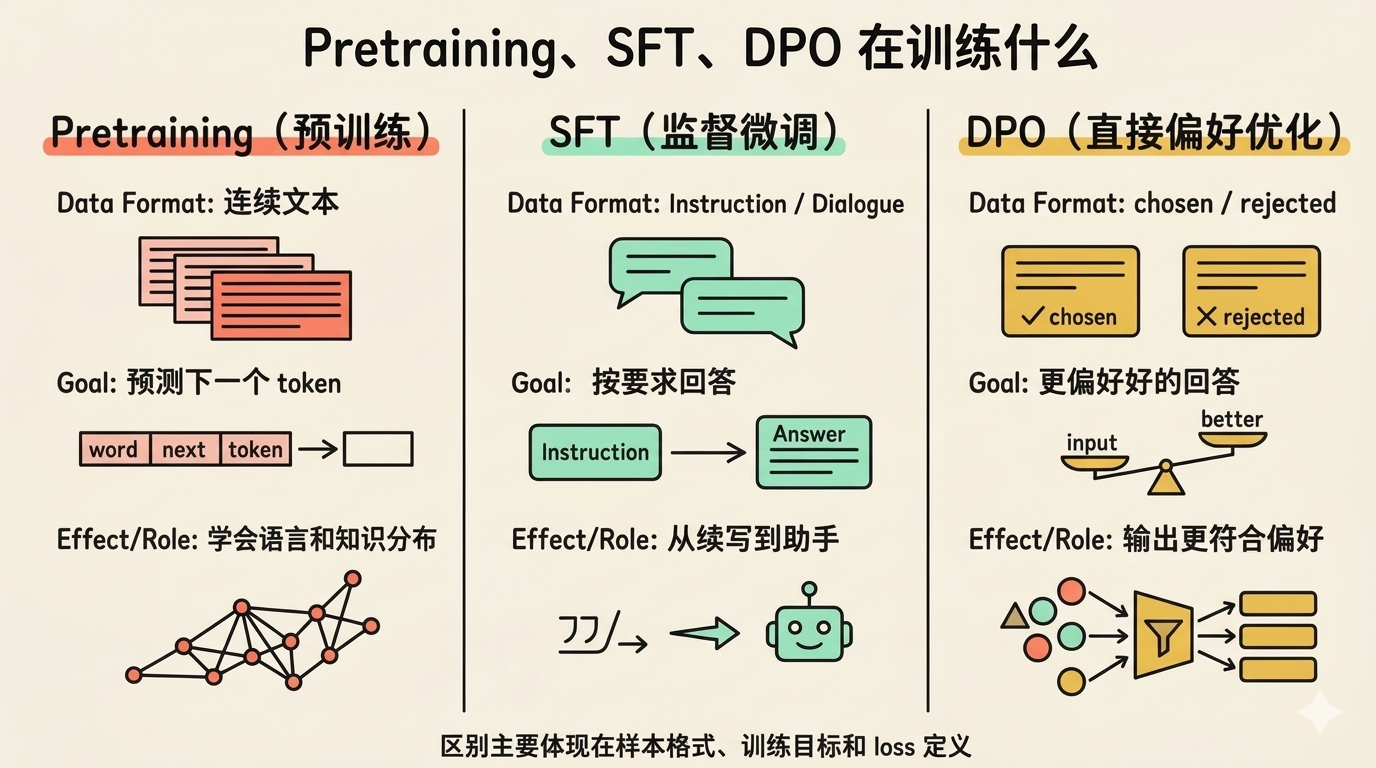
Pretraining、SFT、DPO 分别在训练什么
一开始看训练代码时,会同时遇到这些词:
- Pretraining
- SFT
- DPO
脑子自然会冒出一个问题:既然都是训练,为什么还要分这么多阶段?
本质上,这些阶段不是完全不同的模型结构,而是在不同目标下,对同一个训练主干喂入不同格式的数据,并配上不同的训练目标。
模型主干还是那个模型,但:
- 样本格式不一样
labels(标签,即模型应该预测的正确答案)和mask(掩码,控制哪些位置参与训练)的构造方式不一样loss(损失,衡量模型预测与正确答案之间的差距)的定义也可能不一样
它们分别在解决不同问题。下面我们一个一个来看。
Pretraining(预训练)
这个阶段的数据最朴素——一条样本就是一段连续文本:
{
"text": "今天天气不错,我们去公园散步。"
}经过 tokenizer 变成一串 token id 后,训练目标很直接:给模型前面的 token,让它预测下一个 token。 在 Pretraining 里,labels 就是 input_ids 本身(具体的对齐方式,见下文 shift 一节)——整条序列的每个位置都参与 loss 计算,模型要学会预测序列中每个位置的下一个 token。
通过这个过程,模型逐渐学会语言规律、句法结构、常识和世界知识。
简单说,Pretraining 的作用就是:先把模型训练成会续写、对语言分布有基本感觉的模型。
SFT(Supervised Fine-Tuning,监督微调)
只有 Pretraining 还不够。因为一个只做过预训练的模型,虽然已经有一定语言能力,但它未必稳定地符合人类期待。
比如你问它”什么是 Transformer”,它可能不会像助手那样回答问题,而是接着你的话继续写下去,写出一段看起来像维基百科的文本——因为它在预训练阶段学到的就是”续写”,而不是”回答”。
所以后面通常会有 SFT。
这个阶段的数据不再只是普通文本,而是对话样本:
{
"conversations": [
{"role": "user", "content": "请解释什么是 Transformer"},
{"role": "assistant", "content": "Transformer 是一种基于注意力机制的神经网络架构..."}
]
}训练时,整个对话会被拼成一段序列,但只让 assistant 的回答部分参与 loss 计算——user 的内容会输入模型,但不参与训练,真正重点学习的是 assistant 的输出。具体怎么做到的,下文 labels 和 cross_entropy 两节会展开。
训练目标依然是 next-token prediction,只不过重点从”普通续写”变成了:让模型学会在指令场景下,用期望的方式回答。
所以 SFT 的作用是:把一个”会续写文本”的模型,进一步调成一个”会按要求回答”的助手。
DPO(Direct Preference Optimization,直接偏好优化)
到了这一步,还会出现另一个问题:即使模型已经能回答问题了,它的回答质量也不一定总是让人满意。
比如同一个 prompt,模型可能给出两个都说得过去的回答,但其中一个更清楚、更有帮助、更自然,另一个更敷衍或者更机械。这时就进入偏好优化阶段,DPO 是其中一种常见方法。
DPO 的数据是一组偏好对:
{
"prompt": "...",
"chosen": "...",
"rejected": "..."
}训练目标不是拟合一个标准答案,而是教模型:对于同一个问题,应该更偏好 chosen,而不是 rejected。
与 Pretraining 和 SFT 使用的 cross entropy 不同,DPO 的 loss 对比的是模型在 chosen 和 rejected 上的概率差异。同时,训练过程中还会保留一个冻结的参考模型(reference model),用来防止模型为了迎合偏好而把之前学到的能力也丢掉。
所以 DPO 的作用是:让模型的输出更贴近人类偏好,而不只是”能回答”。
这三个阶段不是割裂的,而是递进的——先有语言能力,才能学指令跟随;先能回答问题,才谈得上回答质量。
最小闭环的数据流长什么样
好了,我们已经知道了三个阶段分别训练什么。接下来就进入代码层面,看看数据在模型里到底是怎么跑的。
虽然三个阶段的样本格式和 loss 不同,但数据在模型内部跑的主干流程是共享的。下面以 Pretraining 为例走通这条最小闭环——SFT 的主要区别在 labels 的构造方式(见 shift 一节),DPO 的差异更大,但核心前向传播流程是一样的。
如果只保留最核心的骨架,大概是这样:
下面我们顺着这条线,一个一个来看。
从语料到 input_ids:先把文本变成模型能处理的编号
训练的起点当然是语料。可能是一段普通文本,也可能是一段对话数据。
但模型不能直接处理”文字”本身,它先要把文本变成 token,再把 token 变成编号。这个过程就是 tokenize。
这里先解释一下几个最容易混淆的词:
- tokenize:把文本切成 token,并映射成编号;执行这个操作的工具就是 tokenizer
- token:模型处理文本时的基本单位,不一定等于”一个汉字”或”一个单词”
- input_ids:token 对应的编号序列,也就是模型输入的整数序列
比如一句话:
我喜欢苹果
经过 tokenizer 之后,不会直接变成”语义”,而是先变成一串 token id,比如:
[35, 82, 419]这里最重要的一点是:input_ids 只是编号,不是向量,也不是模型已经理解后的结果。
它更像是词表里的索引。到了这一步,文本只是从”字符串”变成了”整数序列”。
所以更准确的说法是:文本先进入词表索引空间,变成 input_ids。
Embedding 在做什么:把编号查表变成向量
接下来模型会做 embedding。
这一层的作用,简单说就是:把每个 token id 查表,变成一个连续向量。 这里的”表”本身也是模型参数的一部分,会在训练中不断更新——不是一个固定的编码方案。
如果 input_ids 是:
[35, 82, 419]那么 embedding 之后,每个 id 都会对应一个向量。假设 hidden_size 是 512,那么每个 token 都会变成一个 512 维向量。
这里也解释几个词:
- embedding:把离散编号映射成连续向量
- hidden state / hidden_states:模型内部处理中使用的向量表示
- hidden_size:每个 hidden state 向量的维度
经过这一步,输入从编号变成了向量表示。数据的 shape 也随之变化:
[batch_size, seq_len]
-> [batch_size, seq_len, hidden_size]这里这三个维度可以先这么理解:
- batch_size:一次送进模型的样本数
- seq_len:每条样本的序列长度
- hidden_size:每个 token 被表示成多长的向量
比如:
[8, 128, 512]意味着:
- 一次训练 8 条样本
- 每条样本长度 128 个 token
- 每个 token 被表示成一个 512 维向量
这一步之后,模型才开始在连续向量空间中处理信息。
值得一提的是,实际实现中 embedding 之后通常还会注入位置信息(比如 RoPE,旋转位置编码),让模型能区分 token 的先后顺序。这部分细节后续文章会展开。
容易混淆的地方在于,token id 和 hidden state 常常被当作同一回事。其实两者不是同一个层面的东西:
input_ids是词表索引hidden_states才是模型内部处理的向量表示
多层 block 在做什么:让 token 的表示逐渐带上上下文
embedding 之后,数据会进入多层 Transformer block。
如果先不展开 block 内部的所有细节,只保留主干,它大概是在重复做两件事:
- Attention:让每个 token 融合上下文信息
- MLP:对每个 token 的表示再做一次变换
实际上每层 block 内部还有 Layer Normalization(归一化)和 Residual Connection(残差连接)等组件,它们对训练稳定性很重要,但不影响理解数据流的主线,后续文章会展开。
这一步的一个特点是:shape 往往不变,但语义会不断变化。
经过一层 block 前后,张量形状通常还是:
[batch_size, seq_len, hidden_size]但每个位置上的向量,含义已经不一样了。
原本以为”模型在处理 token”这件事很直接。但实际上,进入 block 之后,每个 token 的表示都会越来越依赖上下文。
举个很粗略的例子:
如果输入是:
我 喜欢 苹果
那么 苹果 这个位置上的表示,经过多层 attention 之后,就不再只是”苹果”这个 token 本身的 embedding 了,而是一个已经融合了前文信息的表示。
因为它已经”看到”了前面的”我”和”喜欢”,这些信息被融合进了当前位置的向量。
所以 block 的作用,不只是”算一遍”,而是:把孤立 token 的向量,逐步变成带有上下文信息的表示。 一层一层,token 越来越”懂”自己所在的语境。
hidden_states 到 logits:为什么还要有一个 lm_head
经过多层 block 之后,模型已经得到了最终的 hidden_states——每个位置上都有一个融合了上下文信息的向量。但训练语言模型时,最终要解决的问题是:下一个 token 是词表里的哪一个?
hidden_states 的维度是 hidden_size(比如 512),而词表(vocab_size,即模型一共认识多少个 token)可能有 50000 个。要让模型对词表里的每个 token 都给出一个分数——表示”下一个 token 是它的可能性有多大”,就需要把 hidden_size 维的向量映射到 vocab_size 维。
这一步就是靠 lm_head 完成的,它本质上是一个线性层。映射之后,每个位置上都会得到一个长度为 vocab_size 的向量,向量里的每个数代表模型认为下一个 token 是词表中对应 token 的可能性。这组分数就叫 logits——它还是原始分数,不是最终概率(转成概率是 cross_entropy 里做的事)。
数据的 shape 变化:
[batch_size, seq_len, hidden_size]
-> [batch_size, seq_len, vocab_size]比如 [8, 128, 512] -> [8, 128, 50000],意味着 8 条样本,每条 128 个位置,每个位置对 50000 个 token 都给出了一个分数。
所以 lm_head 的作用,就是把模型内部的向量表示重新投影回词表空间——只有回到词表空间,模型才有办法表达”下一个 token 更可能是哪一个”。
为什么会出现 labels
到了这里,训练目标才真正清晰起来。
模型已经输出了:
logits.shape = [batch_size, seq_len, vocab_size]它表示的是:一批样本里,每个位置上,模型对整个词表的预测分数。
但模型光输出分数还不够,还需要一个”标准答案”,也就是 labels。
这里的 labels,就是每个位置真正应该对应的目标 token id。
在语言模型里,这个目标通常是”下一个 token”。
所以你可以把训练理解成这样一件事:
- 模型在每个位置上给整个词表打分
labels告诉它正确答案是哪一个 token- 然后用
loss去比较模型打分和真实答案之间的差距
为什么要 shift
语言模型的核心任务是 next-token prediction(下一个 token 预测),也就是:用当前位置的输出来预测下一个 token。 这一点如果不单独拿出来想,很容易糊掉。
训练时真正想做的是:
还是拿前面的例子,假设输入序列是 [我, 喜欢, 苹果],那么:
- 用位置 0(我)的输出预测
喜欢 - 用位置 1(喜欢)的输出预测
苹果 - 用位置 2(苹果)的输出预测下一个 token
所以在代码里,通常会做一个对齐:
shift_logits = logits[..., :-1, :] # 去掉最后一个位置的预测
shift_labels = labels[..., 1:] # 去掉第一个位置的标签这里的 shift,本质上就是”错位对齐”。
它的意思就是:
- 把最后一个
logits丢掉 - 把第一个
labels丢掉 - 让”当前位置输出”和”下一个 token 标签”对齐
这一步就是很多代码里看到的 shift。
这里也回答前面 SFT 留下的问题:SFT 训练时,user 部分的 labels 会被设成 -100,这是 PyTorch 的约定——cross_entropy 遇到 -100 会自动跳过这个位置,不计算 loss。这样就实现了”只训练 assistant 的回答”。shift 之后这些 -100 的位置不受影响,所以 shift 和 mask 不会冲突。
初看时容易把 shift 当成一个额外的步骤。但回想一下,语言模型训练的就是”预测下一个 token”,logits 和 labels 之间需要错位对齐,本来就是这个目标自然带出来的。
cross_entropy 和 loss:模型这次错了多少
有了 logits 和对齐后的 labels,接下来就可以计算损失了。
这里最常见的就是 cross entropy,全称是 cross-entropy loss,中文通常叫 交叉熵损失。
如果不写公式,只保留直觉,它做的事情是:看模型给正确 token 分配了多高的概率。概率越高,loss 越小;概率越低,loss 越大。
更具体一点:logits 是模型输出的原始分数,概念上需要先通过 softmax(把一组分数归一化成概率,所有值加起来等于 1)转换成概率分布,再和 labels(正确答案)计算差距。在代码中,PyTorch 的 F.cross_entropy 直接接收原始 logits,内部完成 softmax 和 loss 计算。得到的结果就是 loss——模型这次答得有多差。
训练的目标,就是让这个 loss 逐步变小。
backward 和 optimizer.step():开始更新参数
到这里,前向传播其实就结束了。
前向这条线做的事情,是:从输入出发,算出 logits,算出 loss。
接下来进入训练更新:
optimizer.zero_grad()
loss.backward()
optimizer.step()分工很清晰:
optimizer.zero_grad():清零上一步的梯度,避免梯度累积loss.backward():根据loss计算每个参数的梯度——梯度可以理解为”loss 对每个参数的敏感度”,它告诉优化器每个参数该往哪个方向调optimizer.step():根据梯度更新参数
所以如果把整条训练主线压缩一下,后半段其实是在做:知道这次哪里错了,然后把参数往更好的方向挪一步。
这里的 optimizer 不是什么神秘模块,本质上就是参数更新规则。比如 SGD、Adam,都是不同的更新方法。
如果说前向传播是在回答:模型这次输出了什么,错了多少?
那么反向传播和 optimizer 在回答的就是:知道错在哪里之后,参数应该怎么改。
术语归位,骨架先立
回过头来看这条主线:训练语料先被 tokenizer 变成 input_ids(输入编号);经过 embedding 变成向量;向量经过多层 block 不断融合上下文优化表示;再通过 lm_head 映射回词表空间,得到 logits(预测分数);和 labels(正确目标)对齐后,用 cross_entropy 计算 loss(误差);最后通过 backward 计算梯度, optimizer 更新参数。
把这些概念放到同一条数据流里理解,就各归其位了。有了这条骨架,后面再去看 attention、RoPE(旋转位置编码)、MoE(混合专家)这些细节,才有落点。attention 里具体怎么计算、为什么有 KV cache,这些都留给后续文章。