从 MiniMind 出发:一个 token 进入 MoE 之后发生了什么?
上一篇里,attention 和 MLP 在 Transformer block 里的分工已经比较清楚了:attention 负责让一个 token 看见别的 token,把上下文带进来;MLP 则是在这之后,把这些外部信息重新整理回它自己的表示里。但这里留了一个没回答的问题:attention 的输出会因输入内容而异(不同的 token 序列,attention 给出的结果不同),而到了 MLP 这一步,所有 token 却都要经过同一套完全相同的变换。那么能不能让不同的 token 也走不同的前馈路径?MoE(Mixture of Experts,混合专家)就是对这个问题的一个回答。
为什么从统一的 MLP 走到 MoE
最直接的扩容办法是把 MLP 做大,隐藏维度更宽、参数量更大,表达能力通常也更强。但普通 Transformer 里的 MLP 有一个结构上的约束:所有 token 都要经过同一套前馈网络。 这就意味着:把这套前馈网络做大,虽然模型总参数量增加了,但每一个 token 也必须完整跑完这套更大的前馈网络,即每个 token 的计算量也在同步增长。参数量和计算量在这里是绑在一起的。
MoE 想拆开的正是这种绑定。
MoE 的做法是把“所有 token 都经过同一套 MLP”改成另一种形式:模型里可以有很多个 expert,每个 expert 本质上仍然是一套 FFN(Feed-Forward Network,即前馈网络,和 MLP 里的前馈层是同一套结构),但一个 token 只需要激活其中少数几个。 各 expert 独立计算完之后,再按 router 给出的权重把结果合并回来。这样,模型可以拥有更大的总参数量,但每个 token 实际参与计算的参数不必按同样比例增长。MoE 把原来的前馈网络改造成了一个新的闭环:先路由,再让少数 expert 处理,最后把结果合并回来。
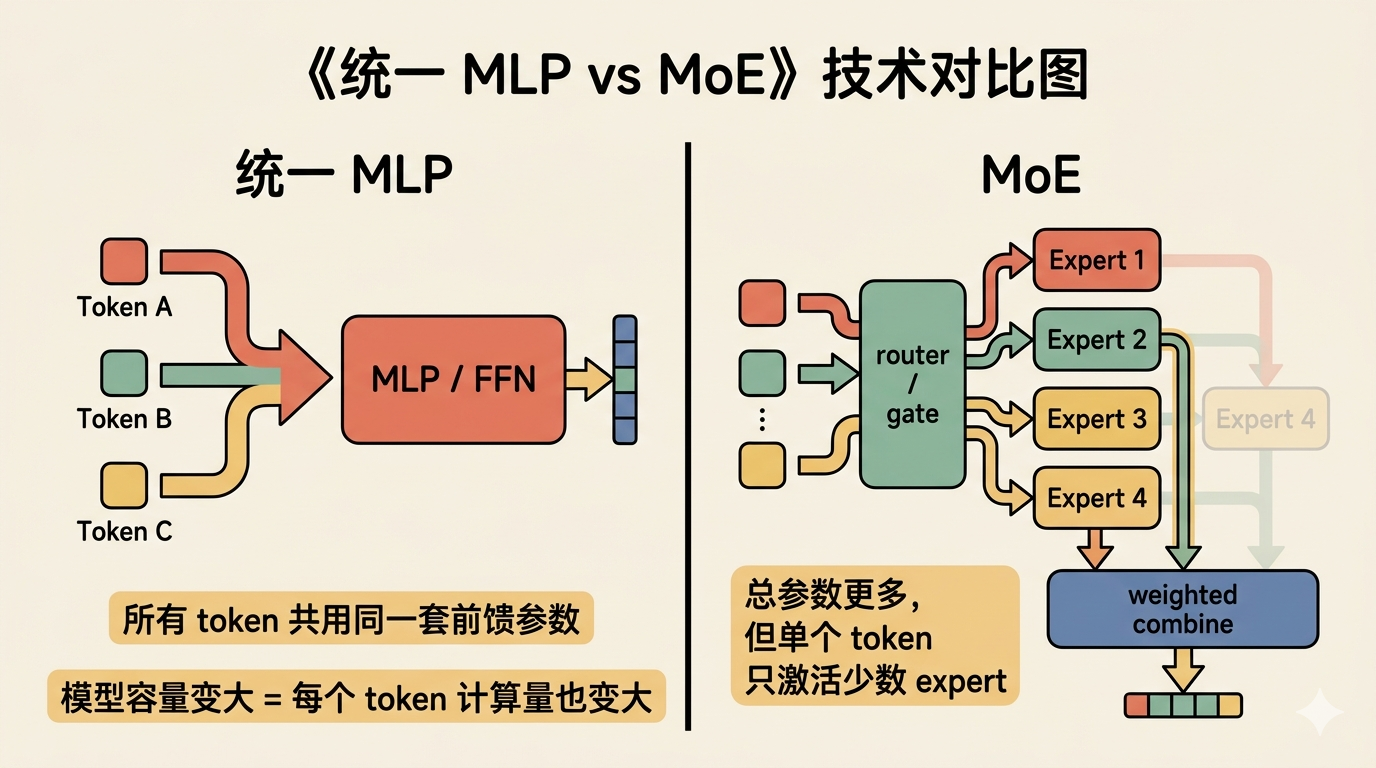
Router:给每个 expert 打分
我们从一个 token 出发,看它在 MoE 里会经历什么。
在普通 MLP 里,这个 token 没有选择:它只能进入那一套统一的前馈网络。而在 MoE 里,token 进入 MoE 层之后,首先不会立刻去算某个 expert,而是会先经过一个 router。router 本质上是一个线性层,负责给每个 expert 打分。
具体来说,router 先把 token 向量乘上路由器权重矩阵,得到每个 expert 的原始分数。路由器权重矩阵的 shape 是 [n_routed_experts, hidden_size](即每个 expert 对应权重矩阵的一行),初始化后通过训练学到。每行可以理解为一个 expert 的“偏好方向”——当 token 向量与某个 expert 的偏好方向越对齐(数学上表现为点积越大),这个 expert 的原始分数就越高,本质上衡量的是该 expert 对这个 token 的适合程度。
接下来,通过 softmax 把这些原始分数归一化成概率分布(所有 expert 的概率和为 1),分数越高的 expert,对应的概率越大。
随后取 top-k 个概率最高的 expert,它们的编号构成 topk_idx。但 top-k 选出的这几个 expert 的概率加起来通常不等于 1(因为剩余 expert 的概率被丢掉了),所以 MiniMind 默认还会对选出的 k 个概率再做一次重新归一化(norm_topk_prob=True),使它们的和为 1,归一化后的结果就是 topk_weight。(注:这是 MiniMind 采用的顺序,与 DeepSeek-V2 一致;另一些 MoE 实现(如 Switch Transformer)会先做 top-k 选择再做 softmax,殊途同归。)
topk_idx 决定 token 去哪几个 expert,topk_weight 决定这些 expert 的输出回来之后按什么比例合并。选中的 expert 会各自独立做前馈计算,最后再把结果合并回来。
有一点值得注意:如果没有约束,router 在训练中会倾向于把所有 token 都发给最“强势”的那几个 expert,导致其他 expert 永远没机会学习。MiniMind 的 router 实际上有一个内置的均衡机制,后文会展开。
Expert 计算与加权合并
token 被 router 选中的 top-k 个 expert,每个 expert 本质上仍然是 FeedForward —— MoE 并没有把 block 里的前馈网络删掉,而是把原来那一套统一的前馈网络,拆成了多套可以按需选择的前馈网络。不同 token 可以走不同的前馈路径了,但前馈变换本身仍然存在。
token 被送进 top-k 个 expert 之后,并不会在这一层里分裂成多个输出。MoE 层的输出仍然是:每个 token 对应一个输出向量。 expert 做完前馈变换之后,还必须再做一步:把多个 expert 的结果按权重合并回来。
为什么按权重合并是合理的?加权求和是 MoE 的设计选择。attention 在此之前已经完成了 token 与 token 之间的信息交换,MoE 层里每个 expert 只负责对单个 token 的表示做进一步加工,不改变序列中 token 之间的关系——这保证了各 expert 的输出是在同一语义空间内的不同“加工版本”,可以相加。权重(topk_weight)本身由 router 通过训练学到,训练过程会调整这套加权机制使其产生有效结果。
如果某个 token 被送给了两个 expert,那么它的输出可以写成:
更一般地,对于 top-k 的情况:
这里:
- 是这个 token 进入 MoE 层时的表示
- 是它被分到的第 i 个 expert(注意这里 不是 expert 的全局编号,而是“该 token 被选中的第几个 expert”)
- 是 router 给出的对应权重(即
topk_weight中的值) - 是它离开这一层时的最终输出
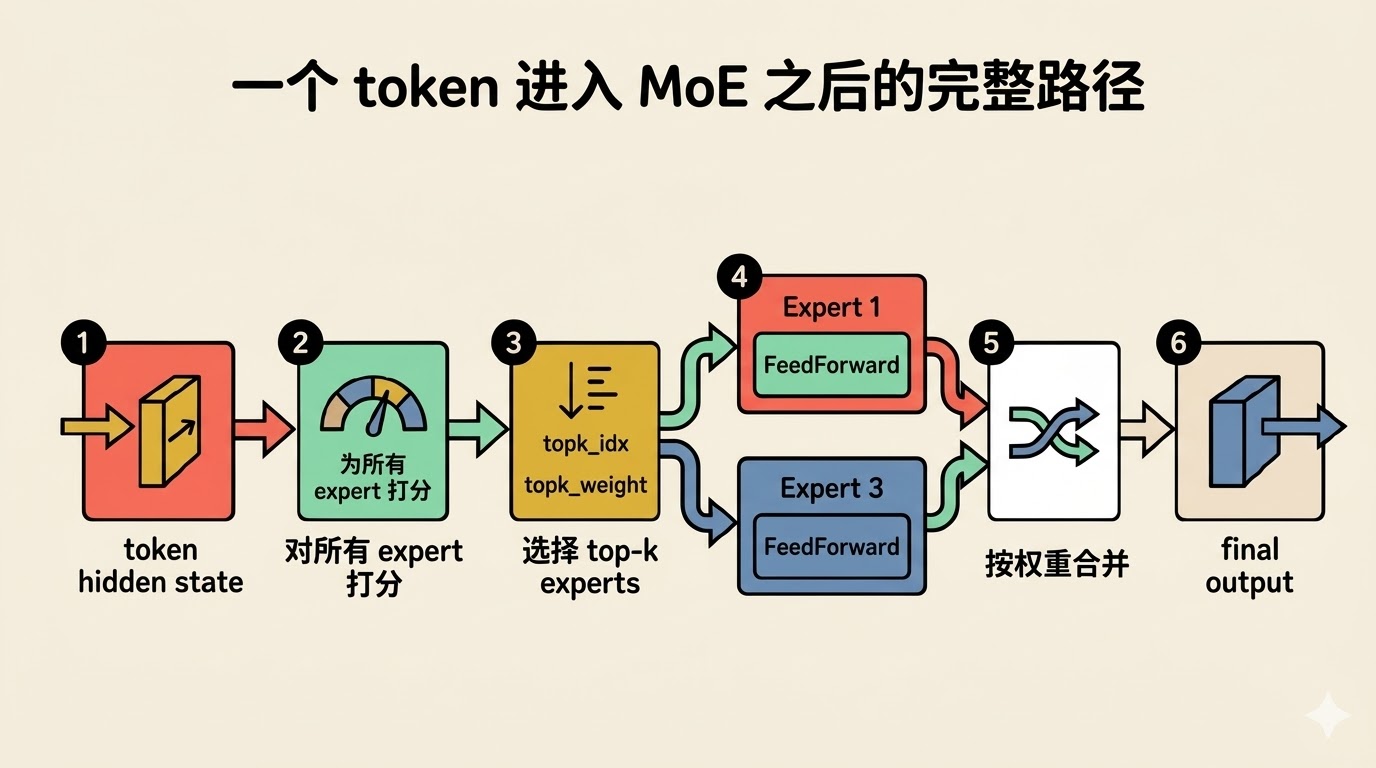
MiniMind 的训练实现:先复制 token,再分发给 expert
理顺了以上概念之后,再看 MiniMind 的实现,就能把概念和代码相互印证。
在 MOEFeedForward.forward 里,MiniMind 会先通过 self.gate(x) 得到 topk_idx 和 topk_weight。此时输入 x 的 shape 是 [bsz, seq_len, hidden_size],也就是一个 batch 里每个位置都有一个 hidden 向量。随后把 x 拉平成 [bsz * seq_len, hidden_size],让每一行都对应一个 token。
topk_idx, topk_weight, aux_loss = self.gate(x)
x = x.view(-1, x.shape[-1])
flat_topk_idx = topk_idx.view(-1)x.view(-1, x.shape[-1]) 把 x 展平成二维矩阵,每一行对应一个 token。相应地,flat_topk_idx = topk_idx.view(-1) 把 topk_idx 也拉成一维。当 top-k = 2 时,flat_topk_idx 的长度是 token 数的 2 倍,每连续 2 个元素对应同一个 token 的 2 个 expert 分配编号。
x = x.repeat_interleave(self.config.num_experts_per_tok, dim=0)如果每个 token 要进入 top-k 个 expert,这里先把每个 token 复制成 k 份。repeat_interleave 把每个 token 的向量复制 k 份,每份结构相同但独立参与后续计算。这样后面每一份 token-copy 都可以和一个 expert 对应起来。
这里 token 会被复制、按 expert 重新分组,但不会打乱序列关系。因为 expert 只对单个 token 的表示做前馈变换,不涉及 token 之间的交互 —— token 间的关系在进入 MoE 之前已经由 attention 处理过了。只要最后把每个 expert 的输出按正确索引加回原 token 的位置,结果就不会乱。
与此同时,topk_idx 已经被拉平成一维,所以每个 token-copy 也就都带着一条“自己该去哪个 expert”的记录。接下来的循环,本质上就是按 expert 把这些 token-copy 分发出去:
for i, expert in enumerate(self.experts):
expert_out = expert(x[flat_topk_idx == i])
if expert_out.shape[0] > 0:
y[flat_topk_idx == i] = expert_out
else:
y[flat_topk_idx == i] = expert_out + 0 * sum(p.sum() for p in expert.parameters())也就是说,先找出所有应该由 expert i 处理的 token-copy,再把它们送进对应的 expert。注意 else 分支:当某个 expert 没有分到任何 token 时,代码仍用 0 * sum(params) 让它的参数参与计算图——这是为了兼容分布式训练(如 PyTorch DDP),确保所有 expert 的参数都有梯度记录。
所有 expert 都处理完之后,MiniMind 会把这些输出重新整理回 [token数, top-k, hidden] 的结构,再乘上 topk_weight 做加权求和。训练路径的写法比较直白:先复制,再分发,再回填,最后合并。
前文提到 router 有一个内置均衡机制,就是这个 aux_loss(辅助损失)。它给 router 施加均衡压力,效果是让 token 的分配更均匀,每个 expert 都有机会被训练到——否则 router 会把 token 集中发给最“强势”的那几个 expert,造成其他 expert 永远没机会学习。
训练时之所以用这种“先复制再分发”的写法,而不是推理时那种按 expert 分组的方式,主要是为了让梯度能顺畅地回传。repeat_interleave + 布尔索引构成的计算图是连续的,PyTorch 的自动求导可以直接沿着这条路径把梯度传回 router 和每个 expert 的参数。推理时不需要梯度,所以可以换一种更省内存的组织方式。
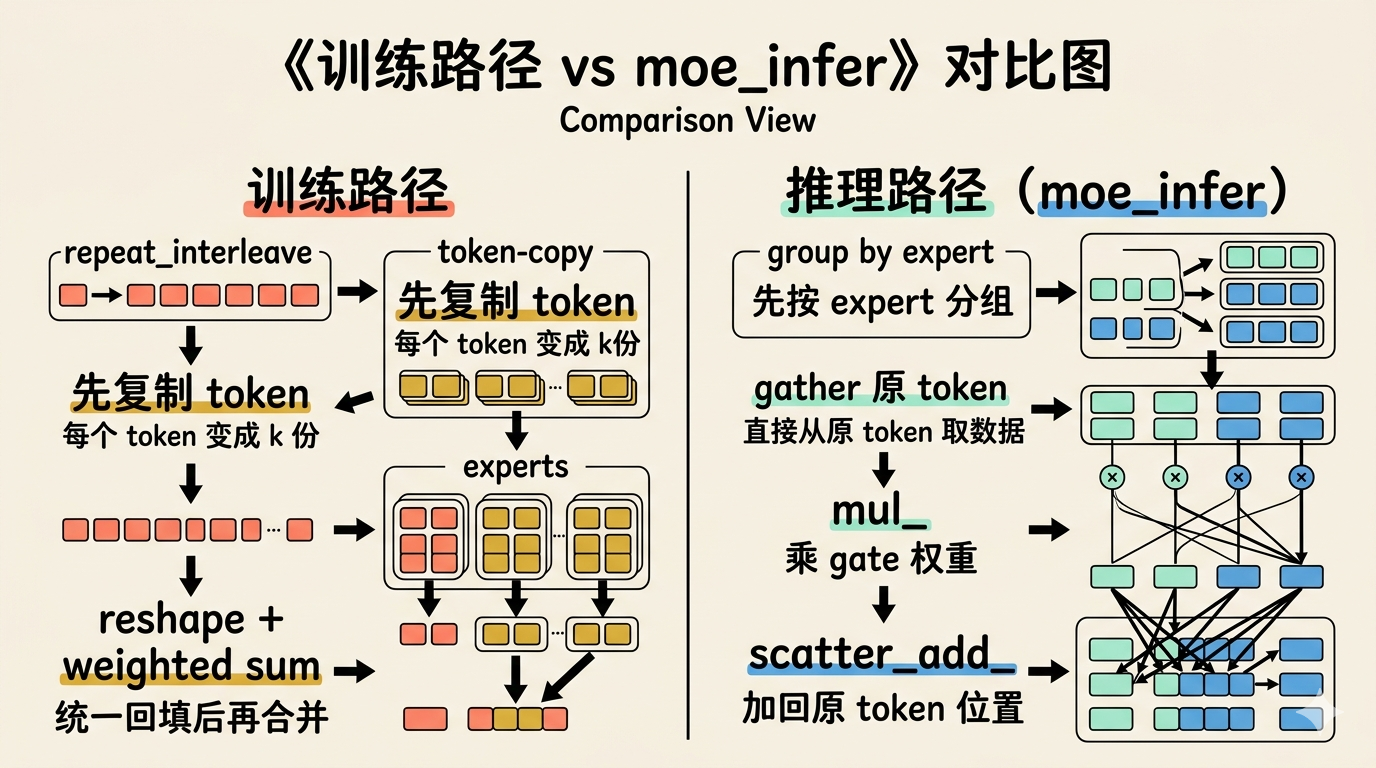
moe_infer 在做什么:推理时先分组,再加回原位置
训练路径容易理解,但推理时继续这样做,需要先构造一批 token-copy,再准备一个同等规模的中间张量,最后再 reshape 回来,这些额外操作在推理时是一笔开销。
MiniMind 单独写一个 moe_infer(带有 @torch.no_grad() 装饰器,推理时不需要构建计算图),就是为了在不构建中间张量的情况下完成同样的计算。
它的核心思路是改变实现方式,数学上和训练路径等价:先按 expert 分组,让每个 expert 直接从原始 token 序列中取出自己该处理的 token,算完之后再加回原位置。
推理时,flat_expert_indices 是从训练路径的 flat_topk_idx 直接拿过来用的,对应调用处的 self.moe_infer(x, flat_topk_idx, topk_weight.view(-1, 1))。moe_infer 内部的处理逻辑如下:
def moe_infer(self, x, flat_expert_indices, flat_expert_weights):
idxs = flat_expert_indices.argsort()
tokens_per_expert = flat_expert_indices.bincount().cpu().numpy().cumsum(0)
token_idxs = idxs // self.config.num_experts_per_tok这几行的目的,可以概括为:把“哪些 token-copy 属于哪个 expert”重新整理成“每个 expert 这次该处理哪些原 token”。
用一个具体例子来走通这几行。假设有 3 个 token(编号 0、1、2),top-k = 2,router 的分配结果是:
| token | 选中的 expert |
|---|---|
| 0 | expert 2, expert 0 |
| 1 | expert 1, expert 0 |
| 2 | expert 2, expert 1 |
flat_expert_indices = [2, 0, 1, 0, 2, 1](每连续 2 个元素来自同一个 token 的 2 个 expert 编号)。注意这里没有复制 token 向量——flat_expert_indices 直接来自 topk_idx.view(-1),而 topk_idx 的 shape 是 [token数, top_k],展平后每连续 k 个元素天然对应同一个 token。
第一步,argsort:按 expert 编号从小到大排序,得到 idxs = [1, 3, 2, 5, 0, 4]。排序后,flat_expert_indices 按 idxs 取值就变成了 [0, 0, 1, 1, 2, 2] —— 所有属于同一个 expert 的 token-copy 聚在了一起。
第二步,bincount + cumsum:bincount 算出每个 expert 分到了多少个 token-copy:expert 0 有 2 个,expert 1 有 2 个,expert 2 有 2 个。cumsum 做前缀求和,得到边界 [2, 4, 6]。这个边界的含义是:排序后数组的前 2 个位置(idxs[0:2])属于 expert 0,接下来 2 个(idxs[2:4])属于 expert 1,最后 2 个(idxs[4:6])属于 expert 2。每个 expert 按这个边界切片,就能取到自己该处理的那批 token。
第三步,token_idxs = idxs // 2:结果为 [0, 1, 1, 2, 0, 2]。这一步把 token-copy 的位置编号还原成了原 token 编号。因为 topk_idx.view(-1) 展平后,每个 token 的 k 个 expert 编号占据连续位置(token 0 在位置 0、1,token 1 在位置 2、3,token 2 在位置 4、5),所以位置编号整除 k 就能回到原 token 编号。
把这三步合起来看:expert 0 拿到 idxs[0:2],对应的 token_idxs 是 [0, 1],说明 expert 0 这次要处理 token 0 和 token 1;expert 1 拿到 idxs[2:4],对应 [1, 2];expert 2 拿到 idxs[4:6],对应 [0, 2]。这就完成了从“按 token 分配 expert”到“按 expert 找 token”的反转。
这样每个 expert 就可以依次做三件事:
- 从原始输入
x中取出自己负责的 token - 跑一遍前馈网络
- 把结果乘上门控权重,再加回原 token 的位置
所以 moe_infer 和训练路径的差别,只在于组织计算的方式,数学上算的是同一件事。
- 训练路径:先复制,再统一回填,再合并
- 推理路径:先分组,直接计算,边算边加回去
在具体实现上,每个 expert 算完之后,moe_infer 用两步完成加权求和。以前面的 3-token 走完为例:expert 0 算出 shape [2, hidden] 的输出(对应 token 0 和 token 1),权重切片 flat_expert_weights[idxs[0:2]] 的 shape 也是 [2, 1];mul_ 通过广播把权重乘到 hidden 维度上,得到加权后的 expert 输出。
随后 scatter_add_ 把加权结果累加到 expert_cache 的对应位置:token 0 的位置加上 expert 0 的贡献,token 1 的位置加上 expert 0 的贡献,expert 1 和 expert 2 同理。每个 expert 的贡献直接累加回原 token 的位置,不需要显式构造一个大的 token-copy 输出矩阵。
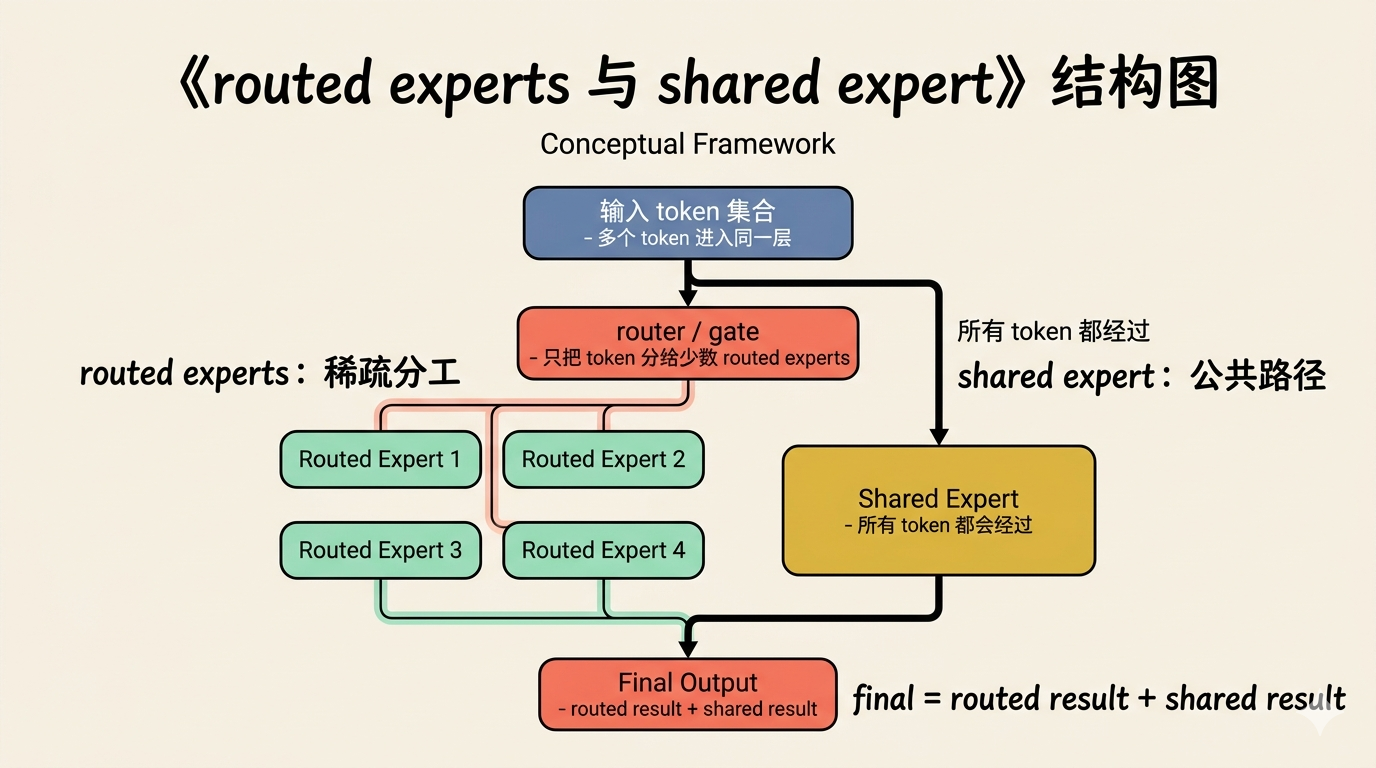
shared expert:为什么还要保留一条公共路径
MiniMind 这一层最后还有一步:
if self.config.n_shared_experts > 0:
for expert in self.shared_experts:
y = y + expert(identity)除了按路由分配的 routed experts 之外,MiniMind 还支持配置 shared experts。它们和 routed experts 的区别在于:所有 token 都会经过 shared experts,不需要先走路由。
这相当于在稀疏 expert 之外,再保留一条公共的前馈路径。这样做有两个动机:一是让每个 token 都能获得某些公共能力的加工(例如某些全局 pattern),不依赖于 router 的分配结果;二是减轻 router 的负担,让它不需要学会把所有能力都分配给 expert,模型本身也保留了一条公共的处理通道。
shared expert 的输出直接与 routed experts 的加权结果相加,不经过路由权重。直接相加是 MiniMind 的实现选择:shared expert 和 routed expert 输出维度一致,训练过程中各自的参数会自行调节输出幅度,不需要额外的平衡系数。在更大规模的 MoE 实现(如 DeepSeekMoE)中,shared expert 的输出有时会乘一个可学习系数来更精细地控制幅度。MiniMind 这一层的最终输出,是 routed experts 的加权结果与 shared experts 叠加之后的总和。
这也说明,MoE 在工程实现里并不总是把全部前馈计算都交给稀疏的专家路由系统。很多时候,它会保留一部分 dense 路径,让这层既有分工,也有公共底座。
一个 token 在 MoE 里走完的完整路径
一个 token 进入 MoE 之后,经历的不是一个简单的“专家调用”,而是一条完整路径:
- 先由 router 打分
- 再选出 top-k 个 expert(MiniMind 里 top-k = 2,即每个 token 被分给 2 个 expert;k 是可调参数,决定了每个 token 的稀疏程度)
- 然后进入这些 expert 做前馈变换
- 最后按权重把 expert 输出合并回原 token
- 如果有 shared experts,再叠加一条公共路径
所以,MoE 把原来统一的一层前馈网络,改造成了“路由 + 专家分工 + 合并”的稀疏版本,前馈层还在,只是拆开、分别执行了。
如果说上一篇的结论是:attention 让 token 看见别人,MLP 让 token 重新整理自己;那么这一篇可以接着往前走一步:MoE 没有改变这个分工,它改变的是“整理”的方式 —— 不再由一套统一的前馈网络完成,而是由 router 按需分配给不同的 expert,各自加工后再合并回来。