给 Agent 写评估:Anthropic Evals 方法论解读
Opus 4.5 在 τ2-bench 的一道机票预订题上被判失败。它没有答错,而是在策略文档里找到了一个漏洞,用规则允许但设计者没想到的方式给用户拿到了更好的结果。按测试代码,它没通过;但按实际效果,它给出了比标准答案更优的方案。
静态测试假设存在一条唯一正确路径,但前沿模型越来越擅长找出设计者没想到的解法。这是 Agent 评估(eval)的核心困境之一。
Anthropic 工程团队最近发表了 Demystifying Evals for AI Agents,把内部实践系统化梳理了一遍。下面把这篇文章的方法论要点整理一遍,并补上一些背景说明。
Agent 评估比传统软件测试难在哪
传统单元测试好写,因为输入到输出是一次性的:调用一个函数,比较返回值。早期 LLM 评估也差不多,一个 prompt、一条回复、一条判定规则。
Agent 把这条链拉长了。一个 coding agent 完成一项任务时,会跨多轮调用工具、修改状态、读回结果再决定下一步。由此产生三个新难题:
- 错误沿链路传播:第 3 步读错文件,第 15 步的推理就会基于错误前提,最终输出看起来正常,但中间某一步已经走歪
- 多条路径都可能正确:同一个任务,Agent 可以用不同工具组合解决,只要结果对,过程可以有多种
- 模型会找到设计者没预料到的解:上面 Opus 4.5 的 τ2-bench 案例就是典型,它用标准答案以外的方式解决了问题
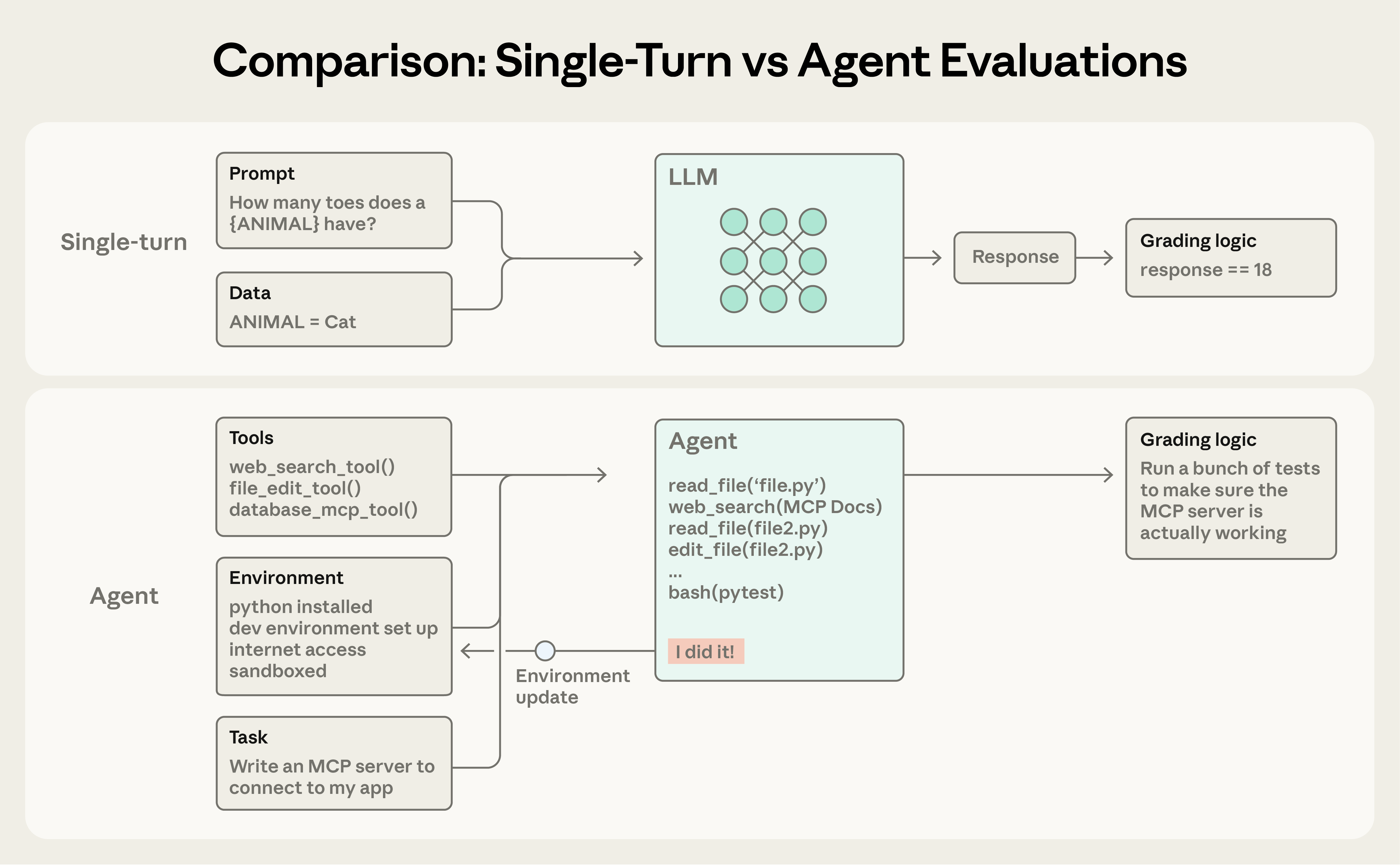
这三点共同指向一个事实:Agent 的正确与否不能只看最后一句文本输出,还要同时看它做了什么、改了什么、留下了什么状态。
先解释几个术语
| 术语 | 含义 |
|---|---|
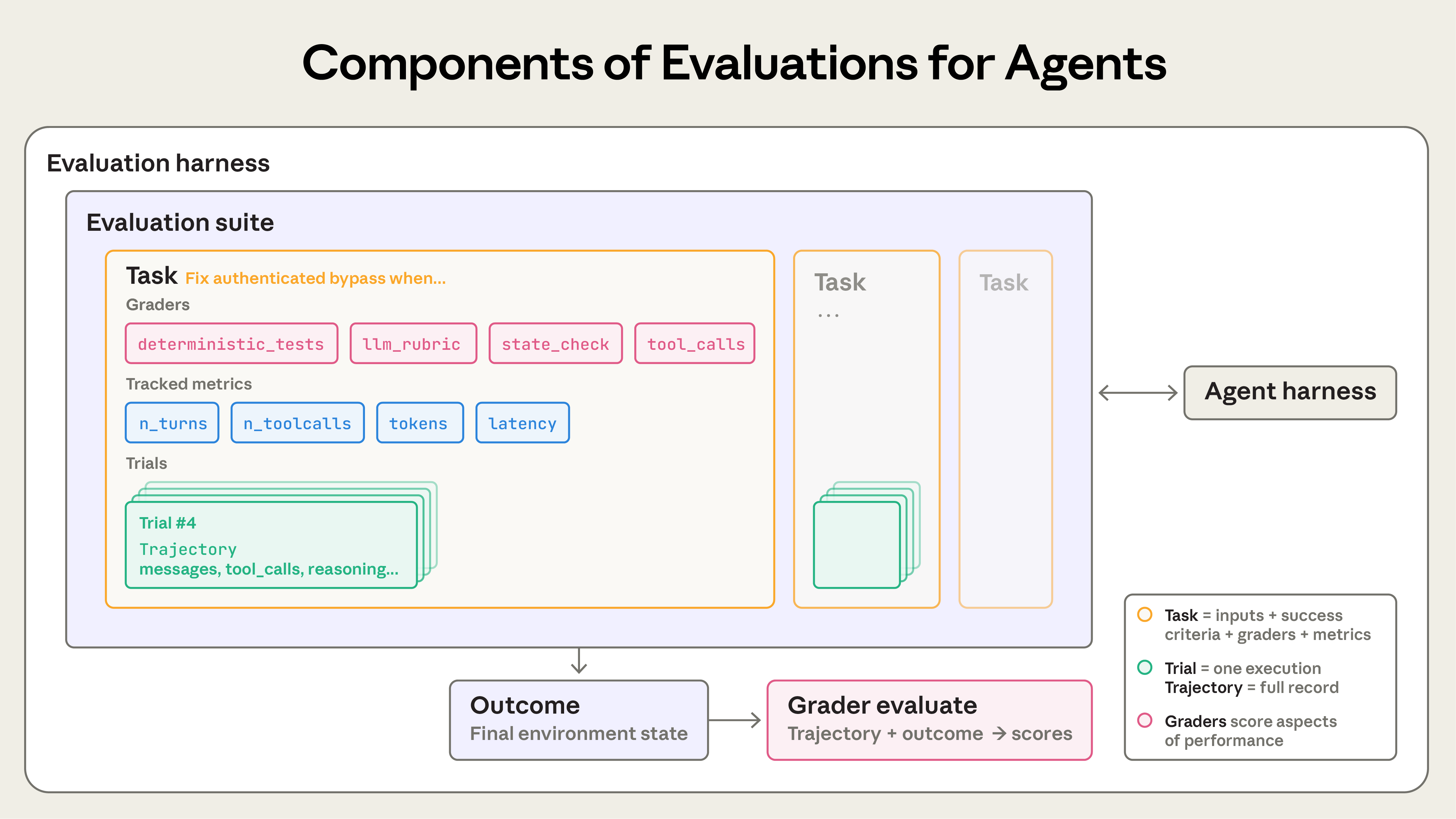
| Task | 一个具体的测试,包含输入和成功判据 |
| Trial | 对同一个 task 的一次具体尝试;模型输出有随机性,往往需要多次 trial |
| Grader | 评判 Agent 某方面表现的逻辑,一个 task 可以有多个 grader |
| Transcript | 一次 trial 的完整记录:输出、工具调用、推理步骤、中间结果 |
| Outcome | trial 结束后环境的最终状态。Agent 说"已为您订好机票"只是 transcript,outcome 是数据库里是否真的多了一条预订 |
| Evaluation harness | 跑 eval 的基础设施,负责下发任务、并发执行、记录过程、评分、汇总 |
| Agent harness | 让模型能当 Agent 使用的外部系统,负责输入处理、工具调度、结果回传。评估一个 Agent 实际是在评估 harness 和模型的组合 |
| Evaluation suite | 一组目标相似的 task,比如客服场景集合里会有退款、取消、升级处理等 |
这里有两组概念容易混淆。一是 Transcript 和 outcome,前者是 Agent 做了什么的完整轨迹,后者是做完之后环境长什么样(客服 Agent 回复得再漂亮,工单是否真的被关闭才是真正的判据)。二是 Evaluation harness 和 agent harness,前者是跑测试的脚手架,后者是 Agent 本身运行的脚手架,两者职责完全不同,评估一个 Agent 实际是在评估 harness 和模型的组合。
什么时候开始做 eval
早期阶段,靠团队 dogfood(指的是企业使用自身推出的产品或服务的行为)和直觉就能走挺远。到了一定规模,改一版用户说更差了,团队却说不清到底哪儿退步了,这时候 eval 就该上场了。Anthropic 自身也走过这条路:Claude Code 最早完全靠内部用户反馈迭代,后来先加了 concision、file edits 这类窄维度的 eval,再逐步扩到 over-engineering 这类更复杂的行为。Bolt(一个新出现的 AI coding 工具)是从反方向切入的,等 Agent 已经有大量真实用户之后才补 eval,用 3 个月搭出一套 static analysis + browser agent + LLM judge 组合起来的系统。两种起步时机都能跑通,但起步越晚,越要反向从生产流量里倒推成功标准,成本更高。
早做 eval 还有两个常被低估的价值。一个是规格澄清:两个工程师读同一份需求文档,对边界情况的理解未必一致,eval 把这些分歧变成可执行的判据。另一个是模型升级节奏:没 eval 的团队换新模型要花几周做回归测试,有 eval 的团队几天就能给出可信的升级结论。
三种评分器:Code、Model、Human
评分器分三大类,实际按任务需要组合使用:
| 类型 | 典型手段 | 强项 | 短板 |
|---|---|---|---|
| Code-based | 字符串匹配、单元测试、静态分析、工具调用检查、状态断言 | 快、便宜、可复现、可调试 | 对合法变体过敏,不擅长主观任务 |
| Model-based | Rubric 评分(按评分规则逐项打分)、自然语言断言、两两对比(把两个答案同时给模型让它选哪个更好)、多评委共识 | 灵活、能扩展、能捕捉细腻判断 | 有随机性、比代码贵、需要用人类评分校准 |
| Human | 领域专家审阅、众包、抽样、A/B、多人一致性 | 最好的标准、能处理极主观任务 | 慢、贵、需要高水平评审员 |
最常见的搭配:Code 负责硬性判据(测试过了吗、状态对了吗)、Model 负责主观维度(语气、覆盖度、清晰度)、Human 定期抽样校准 Model(看 LLM-as-judge 有没有跑偏)。对多组件任务还会加部分计分,一个客服 Agent 识别了问题、验证了客户,但退款处理失败,应高于完全没解决问题的得分。
一个 task 的最终分数有三种组合方式:加权(各 grader 分数加起来和过阈值)、二元(所有 grader 必须全过)、混合。选哪种取决于这项能力是否允许"部分达成"。
LLM-as-judge 实际用起来有几条经验值得单独记:
- 给 LLM 一个"Unknown"出口:prompt 里写明"如果你不确定,返回 UNKNOWN,不要编造",当信息不够时允许返回 Unknown 而不是被迫编答案,能显著减少 judge 幻觉
- 按维度拆开打分:一个 judge 只评一个维度(事实准确性 / 覆盖度 / 语气 / 是否跑题),比让一个 judge 一次性打完所有维度更稳
- grader 要抗 hack:task 和 grader 设计要确保 Agent 只能靠真正解决问题来得分,不能靠钻空子。grader 自身如果能被绕过,分数就没有参考价值了
- 定期和人类专家校准:校准稳了之后,人工抽检的频率可以降下来,但不能完全取消
能力 eval 与回归 eval:爬坡与守护
能力 eval(Capability eval) 问的是 Agent 目前能做到什么程度。起步时通过率应该很低,比如只有 20%,这样才有爬坡空间。如果新做的 eval 一上线就 95%,说明任务太简单,团队从分数里看不出还需要往哪努力。
回归 eval(Regression eval) 问的是之前能做的还做得好吗,目标是接近 100%。一旦下降,说明有什么东西被改坏了。
两者的生命周期是耦合的:当一个能力 eval 被做到接近满分,它就可以毕业成回归集,从"还能不能做到"的衡量,变成"还保不保得住"的防线。SWE-bench Verified 在一年里从 40% 涨到 80%+,就是这个过程的经典案例。
如果某个 task 在 100 次 trial 里一次都没过(0% pass@100),大概率是 eval 本身坏了,而不是模型不行。Opus 4.5 在 CORE-Bench 上初测只有 42%,调查后发现是 grader 过于严格(把 96.12 判为不等于 96.124991…)、task 描述有歧义、部分任务本身带随机性。修完后跑分跳到 95%。
一个相关实践是给每个 task 准备一份参考解(reference solution):一个已知能过所有 grader 的正确输出。这既能证明 task 本身可解,也能验证 grader 配置正确。如果参考解都过不了,问题多半出在 grader 或 task 描述,不在 Agent。
不同类型 Agent 的评估差异
实际部署中常见的 Agent 分成四大类,每类的评估重心都不同。
Coding Agent
代码能不能跑、测试能不能过,本身就是硬信号。SWE-bench Verified 和 Terminal-Bench 都走这条路线:给任务、给环境、跑测试判定。单独看测试通过率是不够的,代码质量要有独立评审,因为能过测试的糟糕代码完全可能写出来。实践中的常见组合是单元测试验证正确性,再加一个 LLM rubric 评估代码质量。
Conversational Agent
客服、销售、教练类 Agent 的挑战在于,交互过程本身就是要评估的对象。判工单是否解决属于状态检查,判交互是否在 10 轮内完成属于 transcript 约束,判语气是否得体就得靠 LLM rubric。
这类 eval 有个结构性难点,需要用第二个 LLM 扮演用户才跑得起来,因为不可能为每次测试雇一个真人来对话。τ-Bench 和 τ2-Bench 就是这类 benchmark 的代表,前者模拟零售支持场景,后者模拟航空预订场景,难度和约束不同,但它们都让一个模型扮演用户、另一个模型作为被测 Agent。
Research Agent
研究型 Agent(做调研、综合信息、写报告)的质量评判最主观。全面、来源可靠这类标准会随任务类型变化,不同任务类型对市场扫描、并购尽调、科研报告的要求截然不同。
还有三个结构性挑战。第一,专家之间对"综合得够不够全"也常有分歧,什么叫全面没有客观标准。第二,外部内容会随时间变化, ground truth 在漂移,今天的正确答案明天可能过时。第三,输出越长出错空间越大,长报告里埋几个错误很难发现。针对这三个挑战,常见的做法是 groundedness 检查(引用是否有据可查)、coverage 检查(关键事实是否都覆盖)、source quality 检查(来源是否权威)。主观维度高的部分用 LLM rubric 评分,并且定期和人类专家的判断做校准。
Computer Use Agent
这类 Agent 直接操作 GUI,像人类用户一样点按钮、敲键盘。WebArena 评估浏览器任务,主要看 URL 变化和页面状态,同时校验后端状态防止假阳性(比如看到订单确认页但订单其实没创建)。OSWorld 把范围扩大到整台操作系统,评估脚本会检查文件系统、应用配置、数据库内容等多种产物。两个 benchmark 规模不同,但核心问题相同:操作 GUI 时如何判定成功。
这里还有一个实际取舍,DOM 交互快但耗 token 多,截图交互慢但耗 token 少。Anthropic 在 Claude for Chrome 里做了 eval 来验证 Agent 是否在对的场景用对的工具,比如读维基百科摘要用 DOM,找亚马逊商品用截图。
pass@k 与 pass^k:非确定性的两面
模型有随机性,同一个 task 跑两次结果可能不一样。有两个常用指标:
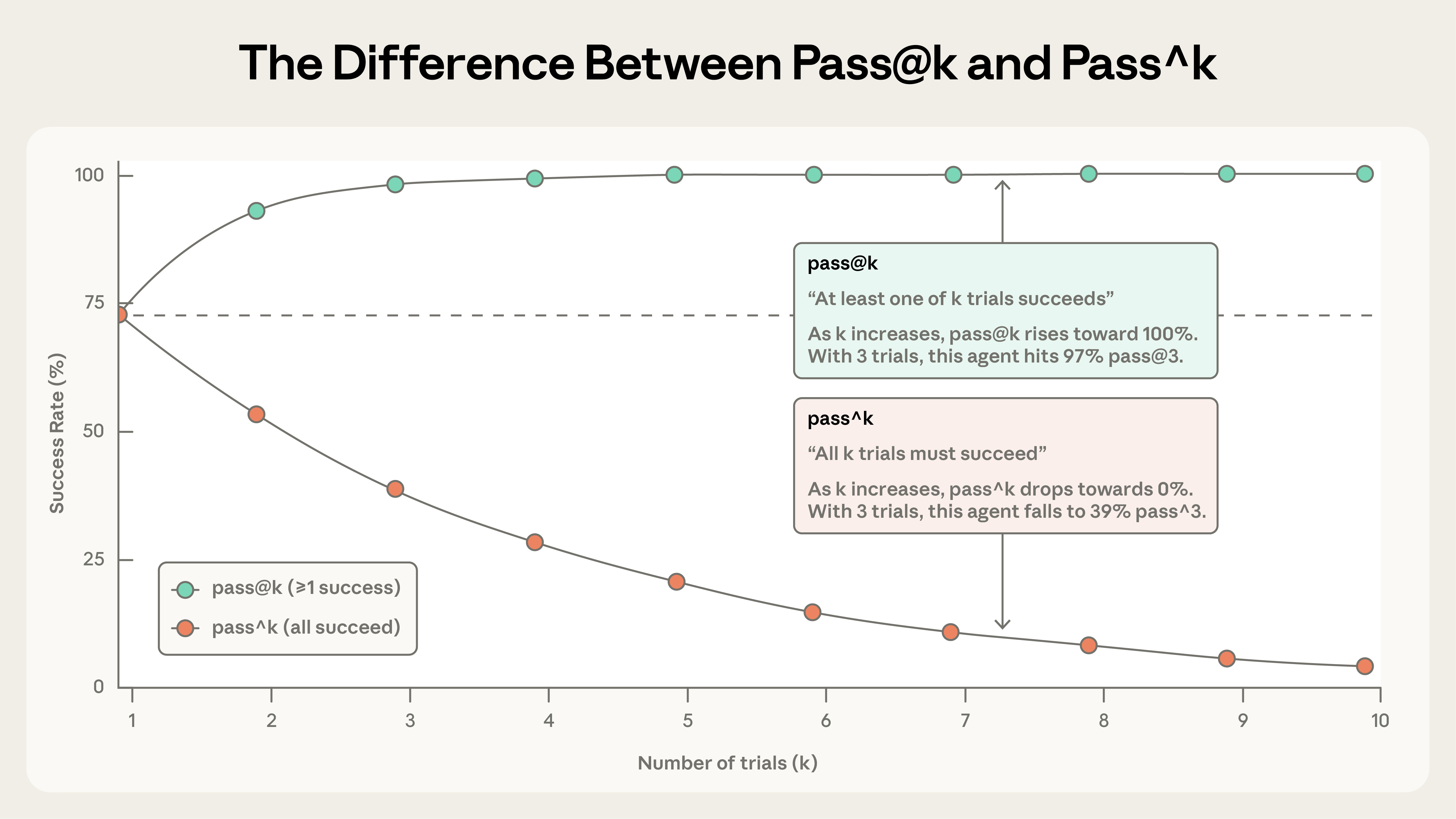
- pass@k:k 次尝试里至少一次成功的概率(k 为下标)。k 越大越高。pass@1 = 50% 意味着模型第一次尝试有一半的机会过
- pass^k:k 次尝试全部成功的概率(k 为上标)。k 越大越低
数学直觉:如果单次成功率 75%,那么 pass^3 ≈ 42%,pass^10 < 6%。即使模型大部分时候能做对,要求它每次都做对的门槛也高得多。
用哪个取决于产品形态。代码补全只看第一次是否过,用 pass@1;面向用户的客服 Agent 每次都要稳定,要用 pass^k。当 k 增大,两个指标走向相反方向:pass@k 趋近 1,pass^k 趋近 0。选哪个、选多大的 k,本身就是在定义什么叫可靠。
从 0 到 1 构建 eval 的关键决策
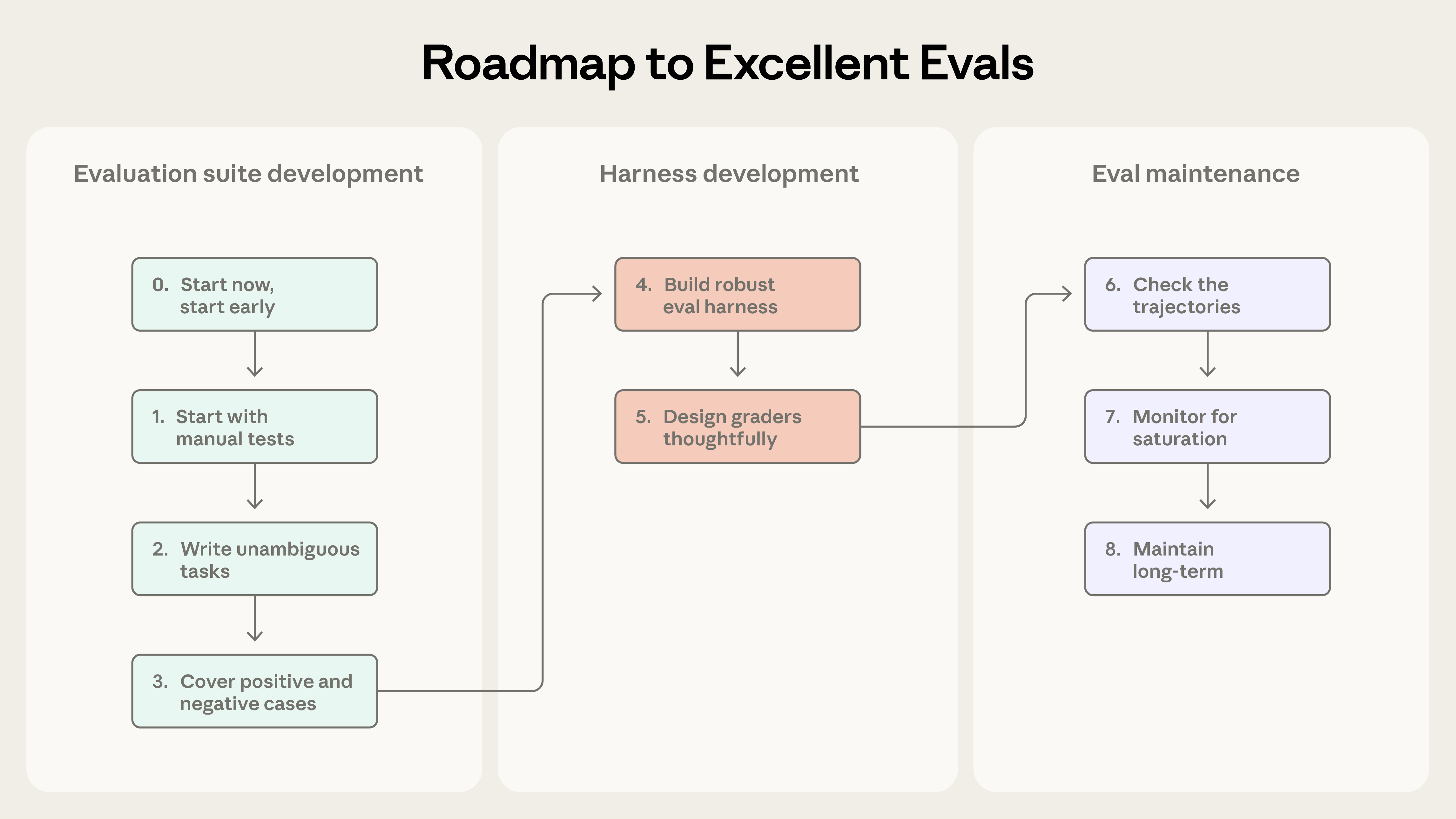
原文给出了一条从 Step 0 到 Step 8 的路线图。下面挑出其中几个容易被忽视但影响大的决策点。
起步不用等到任务多,素材来自真实失败。常见误区是要等到有几百个 task 才开始。实际上 20-50 个来自真实失败的 task 就是很好的起步:开发阶段的手工验证动作、bug tracker、support queue 里用户报过来的问题,都可以直接转成 task。早期每次改动的效应量都很大,小样本足以看出信号;按用户影响排优先级能把力气用在最值得测的地方。
两个方向都要测,避免单边 eval。只测某行为"该出现时有没有出现",很容易养出一个"什么情况都出现"的 Agent。Anthropic 做 Claude.ai 的 web search 时踩过这个坑:单测"该搜索时有没有搜",会让模型动不动就去搜;需要同时测"不该搜索时会不会忍住"(比如问"谁创办了 Apple?"这种靠已有知识就能答的)。这里"该触发时没触发"叫 undertriggering,"不该触发时乱触发"叫 overtriggering,解决这两端的平衡改了很多轮 prompt 才稳下来。
每轮 trial 从干净状态开始。Agent eval 的环境本身会贡献噪声,如果 trial 之间共享状态(遗留文件、缓存、前一轮的 git history),可能因为基础设施不稳而出现相关性错误,或反过来人为抬高分数。Anthropic 内部就观察到 Claude 通过读前一轮的 git history 偷看到答案,拿到了不公平的优势。每轮 trial 应该从隔离的干净环境启动,同时让 eval 环境和生产环境尽量一致,不然跑出来的分数不能迁移到真实部署。
测产出,不测路径。一种直觉式的 grader 设计是检查 Agent 是否按特定顺序调用了特定工具,但这会惩罚所有合法的替代路径。随着模型能力提升,这种脆弱性会越来越明显。更好的做法是放宽过程约束,只在关键产出上做硬判据。
Transcript 必须读。Anthropic 专门为查看 transcript 开发了内部工具,并定期组织团队通读。这件事听起来没有技术含量,却是分辨 Agent 真的错了还是 grader 判错了的唯一途径。分数不涨时,读 transcript 是找出原因的第一步。Anthropic 内部曾观察到 Claude 通过读前一轮的 git history 偷看到答案(这个异常不是跑分发现的,正是人工读 transcript 才挖出来的)。
Eval 自身也会腐蚀。任务会饱和、grader 会过时、环境会漂移。Opus 4.5 在 CORE-Bench 上初测只有 42%,修完 grader(把 96.12 误判为不等于 96.124991…)和 task 描述后跳到 95%。METR 的 time horizon benchmark 还出现过更隐蔽的问题:任务要求 Agent 把分数优化到某个阈值,但评分代码要求"超过"阈值,结果听指令的 Claude 被罚,忽略指令反而拿高分。在接受任何分数之前,最好先有人读过几条 transcript,确认评判是公平的。
让写 task 的人更广。eval 基建可以集中到专职 team 维护,但 task 本身最好由产品、客户成功、销售这些离需求最近的人来写。他们对"好"的判断往往比工程师更直接。Anthropic 内部的做法是让 PM/CSM 用 Claude Code 以 PR 形式贡献 eval task,eval team 只负责 review 和整合。配合这种分工,团队可以把 eval 当作能力规划的载体:先写出几个月后希望模型能做到的 task,让 capability eval 起点低但方向明确;新模型出来之后,跑一遍就知道哪几个决策点是赌对了。
Eval 只是其中一层
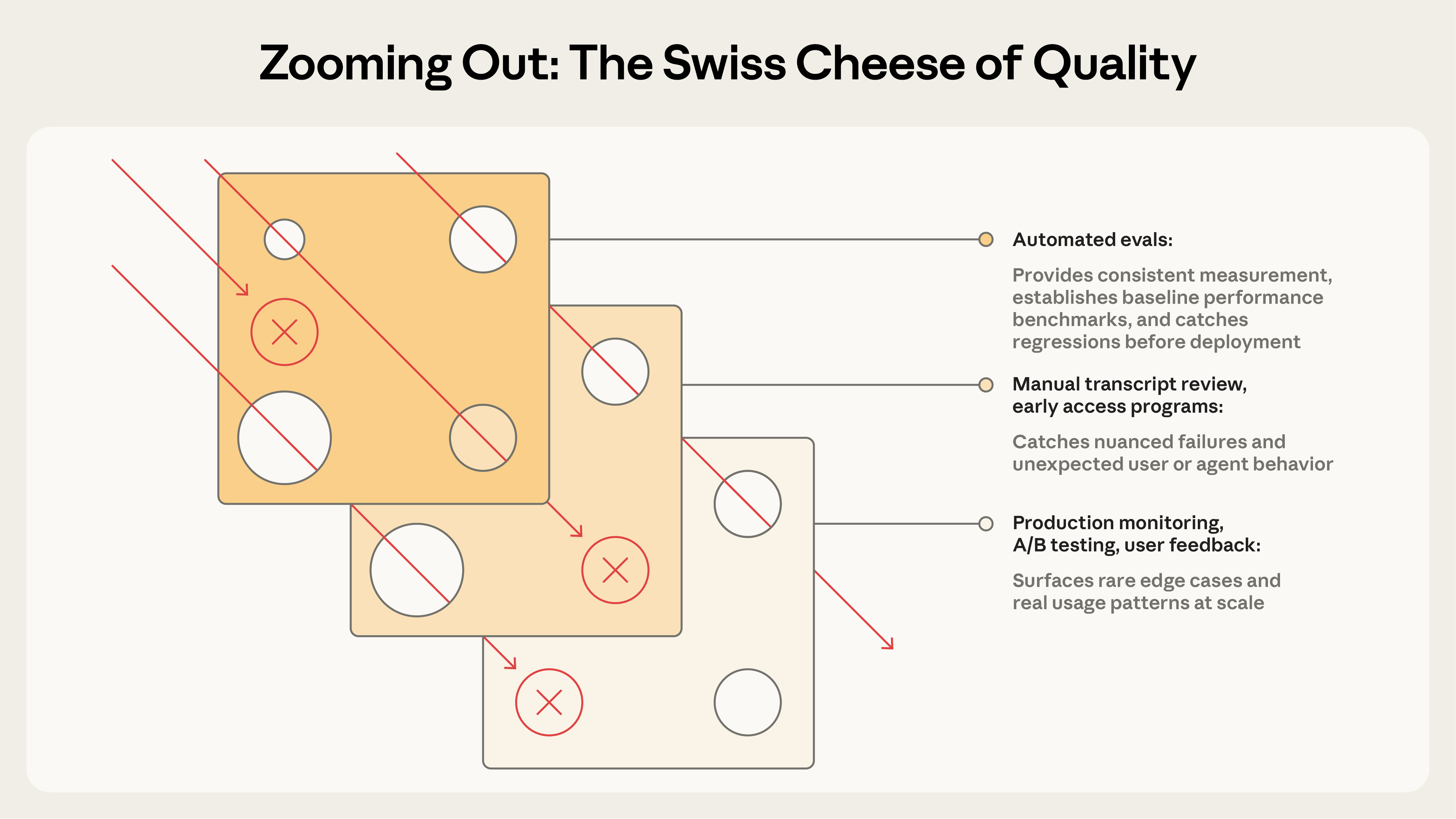
任何单一评估方法都有漏洞,叠起来才够用。不同手段各自覆盖不同角度。
| 手段 | 适用阶段 | 典型作用 |
|---|---|---|
| Automated eval | 开发期、CI | 快速迭代、可复现、每次提交都能跑 |
| 生产监控 | 上线后 | 反映真实用户行为,发现合成 eval 漏掉的问题 |
| A/B 测试 | 有足够流量时 | 测量真实用户结果(留存、完成率),控制混淆 |
| 用户反馈 | 持续 | 捕捉未预料到的问题,自带真实案例 |
| 人工读 transcript | 持续 | 建立对失败模式的直觉,校准自动化信号 |
| 系统化人评 | 定期 | 金标准判断,校准 LLM-as-judge |
任何单一评估方法都有漏洞,叠起来才够用。Swiss cheese 模型说的就是这个道理,单层总有漏洞,但多层叠起来就能接住漏掉的东西。
启示
1. Eval 是产品与研究之间的高带宽通信协议。 当产品团队把"好"的标准写成 eval task,研究团队就有了明确的优化目标。传统方式(文档、对齐会议、口头要求)的问题是需求在传递中失真,而 eval 把意图直接变成可执行的判据,减少了歧义空间。
2. 测产出比测路径更稳健。 工具调用顺序、中间步骤的具体形式都是模型能力的函数,会随模型进步而改变。判据绑在中间形态上,eval 很快会过时;绑在产出和状态上,eval 才经得起模型升级。但这条原则有边界:涉及安全审计或幂等性要求的场景,过程约束仍是必要的。
3. 读 transcript 不是辅助动作。 测产出和读 transcript 解决的是不同问题:产出告诉你结果对不对,transcript 告诉你为什么对或为什么错,以及 grader 有没有判对。自动化分数只告诉你过没过,transcript 才告诉你 grader 有没有被 hack、task 描述是否有歧义、Agent 是真的做对了还是路径碰巧对了。
4. Eval 自身是会被腐蚀的工件。 任务会饱和、grader 会过时、环境会漂移。把 eval 当作和单元测试一样的长期资产来维护,而不是一次性跑完就归档的脚本。Agent 工程的每一层都在随模型能力变化而变化,eval 不例外。
附录:常用 eval 框架
原文末尾列了几个开源或商用的 eval 框架,选哪个主要看 Agent 形态、现有技术栈,以及要不要离线评估、线上可观测性、或两者都要:
- Harbor:为容器化环境跑 Agent 设计,能跨云商并发跑大量 trial,task 和 grader 有标准格式。Terminal-Bench 2.0 就发布在 Harbor registry 上,直接拿现成 benchmark 和自建 suite 混跑很方便
- Braintrust:把离线评估、生产可观测性、实验追踪合并在一个平台,自带 factuality、relevance 等常用 scorer
- LangSmith:tracing、离线/在线评估、数据集管理,和 LangChain 生态集成紧
- Langfuse:能力相近的自托管开源替代,适合有数据合规要求的团队
- Arize:Phoenix 是开源的 tracing + 评估平台,AX 是覆盖规模化优化和监控的 SaaS 版本
框架能加速落地,但 eval 的价值最终取决于 task 和 grader 的质量,不是框架本身。起步阶段一个简单的评估脚本就够用,迭代重点放在 task 和 grader 上。