【π】一次 LLM 调用,如何变成完整的 Agent Run?
上一篇 我们看到了 pi-mono 的全景:packages/ai 负责一次无状态的 LLM(大语言模型,核心能力是根据输入文本预测并生成回复)调用,packages/agent 负责驱动从用户输入到 agent idle 的完整循环,packages/coding-agent 负责一个有状态的编码会话。一次请求从用户输入出发,穿过这三层,最终回到用户面前。
这一篇聚焦前两层:packages/ai 和 packages/agent,看看从"一次 LLM 请求发出",到"整个 agent 循环跑完"是怎么设计的。
一次 LLM 调用的封装
packages/ai 的签名可以用一句话概括:
(Model, Context, Options) → AssistantMessageEventStream它接收模型配置、对话上下文(system prompt + 消息历史 + 工具定义)、运行时选项,返回一个增量事件流。
它不执行工具、不做循环、不维护状态。调用结束,一切结束。
Tool 类型在这一层只有 schema(name、description、parameters JSON Schema),没有 execute 方法。“工具长什么样”是 packages/ai 关心的,“工具怎么执行”不是。
工具调用(tool call)是什么:LLM 在生成文本的过程中,能够在特定位置输出一段结构化的工具调用指令(如 {name: "bash", args: {...}})。LLM 只需要知道有哪些工具可以调用、参数格式是什么,至于工具的实际执行逻辑,那是上层的事。
多 Provider 场景的统一之战
pi-mono 支持 10+ 个 provider:Anthropic、OpenAI、Google、Azure、Mistral、GitHub Copilot、Ollama 等等。每家的 API 格式不同,认证方式不同,甚至同一个 API 协议下不同 URL 的行为也不同。packages/ai 的核心工作之一就是把这些差异消化掉,对外暴露统一的接口。
内部架构分四层:
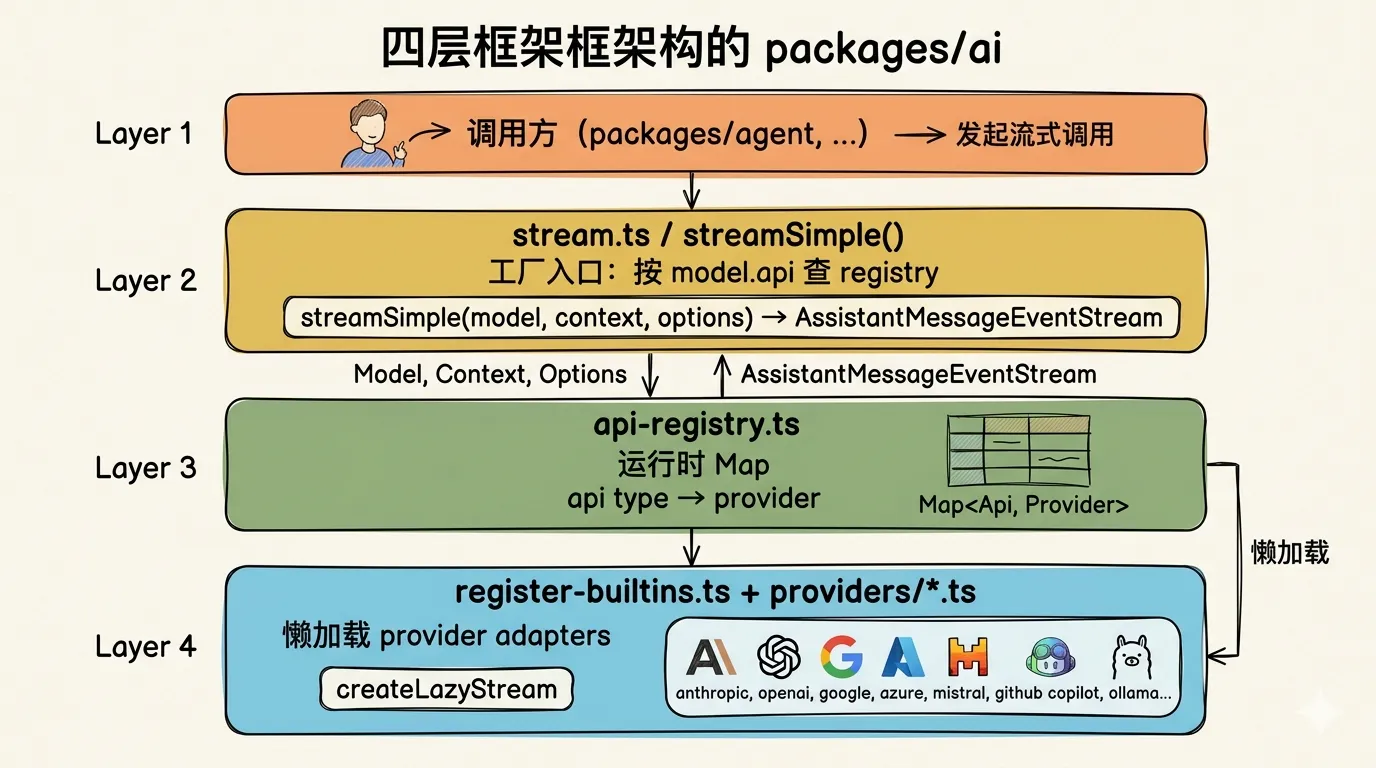
工厂入口 stream.ts 的实现很简洁:
function resolveApiProvider(api: Api) {
const provider = getApiProvider(api);
if (!provider) {
throw new Error(`No API provider registered for api: ${api}`);
}
return provider;
}
export function streamSimple<TApi extends Api>(
model: Model<TApi>,
context: Context,
options?: SimpleStreamOptions,
): AssistantMessageEventStream {
const provider = resolveApiProvider(model.api);
return provider.streamSimple(model, context, options);
}model.api 是一个字符串标识(如 "anthropic-messages"、"openai-completions"),registry 根据它找到对应的 provider adapter,调用 adapter 的 streamSimple 方法。
Registry 的注册用了编译期类型约束:registerApiProvider 要求传入的 stream 函数类型必须与 api 参数匹配,类型不对编译就报错。运行时是一个普通的 Map,编译期是严格的类型门卫。
懒加载是另一个值得注意的设计。10+ 个 provider 的 adapter 不在启动时全部 import,而是用 createLazyStream 包装,第一次调用时才动态加载。如果你只用 Anthropic,Google 和 Ollama 的代码永远不会被加载。
每个 provider adapter 负责三件事:
convertTools():把统一的Tool[]翻译成该 provider 的 tool schema 格式convertMessages():把统一的Message[]翻译成该 provider 的消息格式buildParams():组合最终的 HTTP 请求体
但同一个 API 协议(如 "openai-completions")下,不同 URL 的行为可能不一样。比如 openai.com 用 max_completion_tokens 字段,groq.com 用 max_tokens;有的 provider 要求 tool result 带 name 字段,有的不需要;thinking 块的格式各家也不统一。
这些差异通过 OpenAICompletionsCompat 接口打补丁:
interface OpenAICompletionsCompat {
maxTokensField?: "max_completion_tokens" | "max_tokens";
requiresToolResultName?: boolean;
requiresThinkingAsText?: boolean;
thinkingFormat?: "openai" | "openrouter" | "zai" | "qwen" | "qwen-chat-template";
reasoningEffortMap?: Partial<Record<ThinkingLevel, string>>;
supportsReasoningEffort?: boolean;
supportsStrictMode?: boolean;
// ...
}每个 Model 对象可以携带一个 compat 字段,adapter 在构建请求时根据这些补丁调整行为。大部分字段有基于 URL 的自动检测,compat 是手动覆盖的入口。
这个设计把“API 协议级别的差异”(adapter 处理)和“同一协议下不同 URL 的行为差异”(compat 补丁处理)分成了两层,避免了为每个 URL 都写一个完整的 adapter。
抽象之后的 provider 工厂很简单。这里额外说一下,pi 使用 models.dev 的数据更新 provider 数据。
export function registerBuiltInApiProviders(): void {
registerApiProvider({
api: "anthropic-messages",
stream: streamAnthropic,
streamSimple: streamSimpleAnthropic,
});
registerApiProvider({
api: "openai-completions",
stream: streamOpenAICompletions,
streamSimple: streamSimpleOpenAICompletions,
});
...
}事件流里的 12 种信号
外层消费者(WebUI、agent loop)需要边生成边渲染:看到前几个 token 就开始显示,而不是等完整结果。所以 packages/ai 不返回一个完整的 AssistantMessage,而是返回一个增量事件流。
12 种事件分两组:
生命周期事件(各出现一次):start 表示流开始,done 表示正常结束,error 表示异常结束。
内容块事件(每个内容块一组 start/delta/end):文本块 text、思考块 thinking、工具调用块 toolcall。
完整的类型定义:
type AssistantMessageEvent =
| { type: "start"; partial: AssistantMessage }
| { type: "text_start"; contentIndex: number; partial: AssistantMessage }
| { type: "text_delta"; contentIndex: number; delta: string; partial: AssistantMessage }
| { type: "text_end"; contentIndex: number; content: string; partial: AssistantMessage }
| { type: "thinking_start"; contentIndex: number; partial: AssistantMessage }
| { type: "thinking_delta"; contentIndex: number; delta: string; partial: AssistantMessage }
| { type: "thinking_end"; contentIndex: number; content: string; partial: AssistantMessage }
| { type: "toolcall_start"; contentIndex: number; partial: AssistantMessage }
| { type: "toolcall_delta"; contentIndex: number; delta: string; partial: AssistantMessage }
| { type: "toolcall_end"; contentIndex: number; toolCall: ToolCall; partial: AssistantMessage }
| { type: "done"; reason: Extract<StopReason, "stop" | "length" | "toolUse">; message: AssistantMessage }
| { type: "error"; reason: Extract<StopReason, "aborted" | "error">; error: AssistantMessage };所有 delta 事件都带一个 partial 字段,表示当前累积到此刻的完整 AssistantMessage。外层拿到 text_delta 时,既可以只用 delta 做增量渲染,也可以用 partial 拿到完整的中间状态。
一个 Anthropic 请求的事件传递看起来像这样:
SDK 事件 packages/ai 事件
─────────────────────────────────────────────────────
message_start → start { partial }
content_block_start(text) → text_start { contentIndex: 0 }
content_block_delta(text) → text_delta { delta: "我来帮" }
content_block_delta(text) → text_delta { delta: "你查" }
content_block_stop → text_end { content: "我来帮你查" }
content_block_start(tool) → toolcall_start { contentIndex: 1 }
content_block_delta(input) → toolcall_delta { delta: '{"arg' }
content_block_delta(input) → toolcall_delta { delta: 'ument' }
content_block_stop → toolcall_end { toolCall: {...} }
message_delta(stop_reason) → done { reason: "toolUse" }每个 provider 的 SDK 事件格式不同,adapter 把它们翻译成统一的 12 种事件。上层代码不需要关心底层用的是 Anthropic 还是 OpenAI。
还有一个设计细节:错误编码进流,不抛异常。请求失败、运行时错误都通过 error 事件交付,不会 throw。这保证了事件流的契约始终成立:消费者用 for await 迭代,最后一定能拿到 done 或 error,不需要额外的 try/catch。
EventStream:push 与 pull 的握手协议
AssistantMessageEventStream 是这一层最重要的设计之一。
为什么需要流式返回:如果等 LLM 生成完整个回复再返回,用户就只能干等——看不到前几个 token,必须等完整结果出来才有反馈,体验很差。外层消费者(WebUI、agent loop)需要边生成边渲染,所以不返回完整的 AssistantMessage,而是返回增量事件流。
怎么设计:producer 是一个 SSE 流,是 push-based 的(LLM 一吐就推过来),consumer 是一个 for await,是 pull-based(主动要下一个)。两端节奏不一致时,谁先到谁要等:producer 快就要缓冲,consumer 快就要挂起等待。公共 EventStream 用一个 queue 数组承接多出来的 provider 事件,再用一个 waiting 数组记录挂起的 consumer。
让我们来看代码,EventStream<T, R> 是一个泛型类,T 是流式事件类型,R 是最终结果类型。核心只有 60 多行,consumer 端 for await 取事件,producer 端 push 推事件:
class EventStream<T, R = T> implements AsyncIterable<T> {
private queue: T[] = [];
private waiting: ((value: IteratorResult<T>) => void)[] = [];
private done = false;
private readonly isComplete: (event: T) => boolean; // 外部定义
private readonly extractResult: (event: T) => R; // 外部定义
...
}需要考虑两种情况:
Path A:producer 更快。产生数据时发现没有消费者在等,事件进 queue 数组存起来,等待被消费。
Path B:consumer 更快。消费者来消费的时候发现现在没有数据且流未结束,注册 waiting 等待数据生成。等生产者产生数据时发现有 waiter,就能直接发给消费者,事件零缓冲地交付。
// producer
push(event: T): void {
if (this.done) return; // done 后静默丢弃
if (this.isComplete(event)) { // 终止事件
this.done = true;
this.resolveFinalResult(this.extractResult(event));
}
const waiter = this.waiting.shift(); // 有消费者在等吗?
if (waiter) waiter({ value: event, done: false }); // Path A 直接交付
else this.queue.push(event); // Path B 没人等,进队列,等待被消费
}// consumer
async *[Symbol.asyncIterator](): AsyncIterator<T> {
while (true) {
// Path A:队列有数据吗?有就直接取
if (this.queue.length > 0) {
yield this.queue.shift()!;
}
// 流已结束
else if (this.done) {
return;
}
// Path B:现在没有数据且未结束,注册 waiting 等待数据生成
else {
const result = await new Promise<IteratorResult<T>>(
(resolve) => this.waiting.push(resolve)
);
if (result.done) return;
yield result.value;
}
}
}字段 done 的语义 需要留意,表示 Stream 结束发出了终止事件(如 done 或 error event)。Stream 关闭后,后续所有事件都会被静默丢弃。
result() 方法则提供了另一种使用方式:它返回一个 Promise,在 Stream 终止时 resolve。同一个 EventStream 实例既支持流式消费(for await),也支持一次性获取最终结果(await stream.result())。
基础的 EventStream 讲完了,接下来就是 AssistantMessageEventStream 这个泛型类的预配置子类:
class AssistantMessageEventStream
extends EventStream<AssistantMessageEvent, AssistantMessage> {
constructor() {
super(
// isComplete,判断 stream 是否结束
(event) => event.type === "done" || event.type === "error",
// extractResult,提取 stream 的最终结果,类型为 AssistantMessage
(event) => {
if (event.type === "done") return event.message;
if (event.type === "error") return event.error;
throw new Error("Unexpected event type for final result");
},
);
}
}这个设计最漂亮的地方在于跨层复用。
同样的 EventStream 泛型,在 packages/ai 层桥接 LLM provider 和 agent loop:
// packages/ai 层:provider push 事件,agent loop 消费
EventStream<AssistantMessageEvent, AssistantMessage>在 packages/agent 层桥接 agent loop 和 UI/CLI:
// packages/agent 层:agent loop push 事件,UI/CLI 消费
EventStream<AgentEvent, AgentMessage[]>同一个 60 行的泛型类,桥接了整个架构的两层边界。
stream 与 streamSimple
packages/ai 暴露了两个入口函数:stream 和 streamSimple。区别在于对 thinking/reasoning 参数的处理方式。
stream 暴露 provider 的原始参数:如果你想精确控制 Anthropic 的 thinking.budget_tokens 或 OpenAI 的 reasoning_effort,直接使用这个入口。但这意味着调用方必须知道自己在跟哪个 provider 对话。
streamSimple 在 StreamOptions 基础上多了两个统一字段:
interface SimpleStreamOptions extends StreamOptions {
// "minimal" | "low" | "medium" | "high" | "xhigh"
// 是不是很熟悉 *^o^* ,openclaw 中的定义就是从这来的
reasoning?: ThinkingLevel;
thinkingBudgets?: ThinkingBudgets;
}调用方说“我要 medium 级别的 reasoning”,streamSimple 内部根据 provider 类型自动翻译:对 Anthropic 映射成 thinking.budget_tokens,对 OpenAI 映射成 reasoning_effort,对不支持 thinking 的 provider 静默忽略。
packages/agent 默认用 streamSimple,因为 agent 层不应该关心底层用的是哪个 provider。streamSimple 提供了统一的 reasoning 参数映射,agent 只需说“我要 medium reasoning”而无需翻译成具体 provider 的参数名。
从输入到 idle 的 agent run
先定义两个概念:
turn = 一次 assistant response + 它触发的那一轮的工具调用和结果;
agent run = 从用户输入到 agent idle 的完整循环,由一个或多个 turn 串起来。
packages/agent 接管 agent run 的全过程。它负责循环控制、工具执行、event emit。
AgentContext:agent run 的输入快照
agent run 的输入是一个 AgentContext,它是一个精简的上下文快照:
interface AgentContext {
/** 系统提示词 */
systemPrompt: string;
/** 对话历史,模型能看到的所有消息 */
messages: AgentMessage[];
/** 本次 run 可用的工具列表 */
tools?: AgentTool<any>[];
}三个字段覆盖了 agent 运行所需的全部输入:模型看到什么提示词、看到什么对话历史、能调用什么工具。它不知道 session 是什么、不知道 compaction 是什么、不知道 system prompt 怎么构建。这些都是外层的职责。
边界清晰了,那么 AgentTool 具体如何补足可执行性?
AgentTool:从 schema 到可执行
packages/ai 的 Tool 只有描述性质的 schema:name、description、parameters。LLM 需要看到的就是这些。
packages/agent 的 AgentTool 在 Tool 基础上补足了可执行性:
interface AgentTool<TParameters extends TSchema = TSchema, TDetails = any> extends Tool<TParameters> {
/** 人类可读标签,UI 显示用 */
label: string;
/** 执行前的参数预处理/兼容处理 */
prepareArguments?: (args: unknown) => Static<TParameters>;
/** 实际执行逻辑 */
execute: (
toolCallId: string,
params: Static<TParameters>,
signal?: AbortSignal,
onUpdate?: AgentToolUpdateCallback<TDetails>,
) => Promise<AgentToolResult<TDetails>>;
}三个新增能力:
execute是核心,接收 toolCallId 和校验后的参数,返回执行结果。signal用于中断,onUpdate用于流式输出中间结果(比如 bash 命令的实时输出)。prepareArguments在 schema 校验前对原始参数做预处理。LLM 有时候会输出格式略偏的参数(比如字符串化的 JSON),这个钩子让工具有机会修正。label是给人看的。LLM 看到的是name(如"bash"),用户在 TUI 里看到的是label(如"Execute bash command")。
runLoop:一次 run 里的多个 turn
在深入代码前,先理解两个队列的语义:
- steering 是“agent 还在干活时就追加输入/任务”。等当前正在执行的工具跑完后触发一次新的 turn。它不会打断正在执行的工具调用,但会让 agent 多跑一个 turn。
- follow-up 是“agent 本来活全部干完了准备要停了,但在这个时候追加输入/任务”。它在 agent 即将 idle 时被检查,如果有消息就再触发一次新的 turn。
注意:两者都会触发新的 turn,真正的差别是检查时机。用户在 agent 执行过程中又输入了一句话,这句话会以 user message 形式加进消息队列,但是具体进哪个队列是可以根据 agent 的配置来改变的。
runLoop 是 agent 的核心驱动逻辑,一个双重 while 结构:
// 外层:follow-up 消息驱动新 turn
while (true) {
let hasMoreToolCalls = true;
// 内层:工具调用 + steering 消息驱动新 turn
while (hasMoreToolCalls || pendingMessages.length > 0) {
// 注入 pending 消息(来自 steering)
if (pendingMessages.length > 0) {
for (const message of pendingMessages) {
currentContext.messages.push(message);
}
pendingMessages = [];
}
// 发给 LLM,拿到回复
const message = await streamAssistantResponse(/*...*/);
// 检查是否有工具调用
const toolCalls = message.content.filter(c => c.type === "toolCall");
hasMoreToolCalls = toolCalls.length > 0;
if (hasMoreToolCalls) {
const toolResults = await executeToolCalls(/*...*/);
for (const result of toolResults) {
currentContext.messages.push(result);
}
}
// 查 steering 队列
pendingMessages = (await config.getSteeringMessages?.()) || [];
}
// 内层退出 = 没有 tool calls 且没有 steering 消息
// 查 follow-up 队列
const followUpMessages = (await config.getFollowUpMessages?.()) || [];
if (followUpMessages.length > 0) {
pendingMessages = followUpMessages;
continue; // 回到外层,开始新 turn
}
break; // 完全退出
}内层 while 连续运行多个 turn。每轮迭代就是一个 turn:发起一次 LLM 调用、处理这次返回的工具调用、然后检查 steering 队列。只要模型还在调工具、或者 steering 队列里有新消息,内层就进下一个 turn。turn_start/turn_end 事件就是对应这里每一次 turn 的起止。
外层 while 在内层彻底退出后检查 follow-up 队列。内层退出意味着:最近的一个 turn 已经结束、模型没再调工具、steering 也空,agent 可以准备 idle 了。这时 follow-up 给了一次追加任务的机会,有 follow-up messages 就让内层继续跑下一个 turn,没有的话这次 agent run 就正式结束了,等待下一轮用户输入。agent_start/agent_end 事件就是对应这里每一次 agent run 的起止。
并发启动,按序回收
当一个 assistant 消息包含多个 tool calls 时,默认采用并行执行:
// 全部同时启动
const runningCalls = runnableCalls.map((prepared) => ({
prepared,
// 非阻塞异步调用
execution: executePreparedToolCall(prepared, signal, emit),
}));
// 按原始顺序逐个 await
for (const running of runningCalls) {
const executed = await running.execution;
results.push(
await finalizeExecutedToolCall(/*...*/ running.prepared, executed, /*...*/),
);
}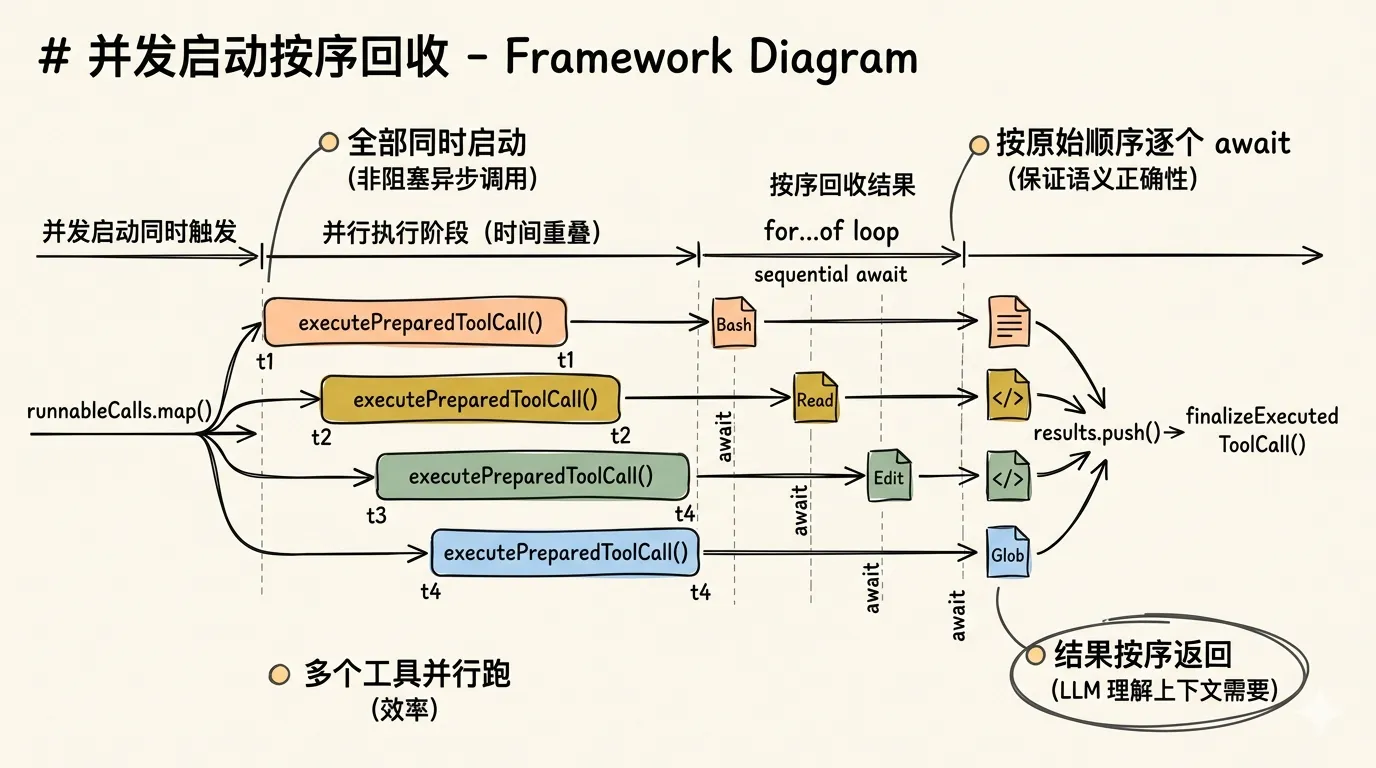
多个工具调用同时执行,但结果必须按调用顺序返回。这是因为大部分 provider 需要组装 tool call 和 tool call result 交给 LLM,工具结果的顺序必须和工具调用的顺序一致,才能让 LLM 正确理解哪个结果对应哪个调用.这样实现同时满足了执行效率(工具并行跑)和语义正确性(结果按序返回)。
为什么每层都需要定义自己的消息类型?
packages/ai 的 Message 只有三种角色:user、assistant、toolResult,这是 LLM 能理解的全部。但应用层可能需要自定义消息类型,比如 UI 通知、artifact 展示、状态标记。这些消息不应该发给 LLM,但需要存在于对话历史中。这和传统开发过程中定义 DTO、BO、DO 的思路类似:不同层有不同的关注点和职责范围,消息类型也应该根据层的职责来定义。
// packages/ai
type Message = UserMessage | AssistantMessage | ToolResultMessage;
// packages/agent
type AgentMessage = Message | CustomAgentMessages[keyof CustomAgentMessages];
interface CustomAgentMessages {
// Empty by default - apps extend via declaration merging
}CustomAgentMessages 是一个空接口,应用层通过 TypeScript 的声明合并来扩展自己的字段:
declare module "@mariozechner/agent" {
interface CustomAgentMessages {
// example
artifact: ArtifactMessage;
notification: NotificationMessage;
}
}这样 AgentMessage 就自动包含了 ArtifactMessage 和 NotificationMessage。
两层消息模型意味着需要两条转换流水线:
transformContext:AgentMessage[] → AgentMessage[]。不改变消息类型,改变消息内容或数量。典型用途是 context window 管理,对话太长时裁掉旧消息。convertToLlm:AgentMessage[] → Message[]。跨越类型边界,把应用层消息翻译成 LLM 能认的格式。自定义消息要么转成 user message,要么直接过滤掉。
agent run 的 hook:callback 的边界
packages/agent 定义了循环的骨架,但循环中每个关键节点的具体行为(消息怎么转、模型认证、消息插队、工具能不能跑、上下文管理等等)通过 AgentLoopConfig 定义的 callback 全部委托给上层决定。这个分界让 packages/agent 可以被不同的上层复用(不只是 coding-agent,也可以是 chat-agent、data-agent)。
| Callback | 作用 |
|---|---|
convertToLlm | AgentMessage[] → Message[],跨层消息转换 |
transformContext | AgentMessage[] → AgentMessage[],context 窗口管理 |
getApiKey | 动态获取 API key(OAuth token 可能过期) |
getSteeringMessages | 获取 steering 队列的消息 |
getFollowUpMessages | 获取 follow-up 队列的消息 |
beforeToolCall | 工具执行前拦截(可阻止执行) |
afterToolCall | 工具执行后修改结果 |
这 7 个 callback 就是 packages/coding-agent 注入具体行为的接口。packages/agent 不知道也不需要知道 packages/coding-agent 的存在。它只知道有一组 callback,调用它们,拿到结果,继续循环。
AgentEvent 生命周期
packages/agent 通过观察者模式向外发射事件。事件分四类:
type AgentEvent =
// Agent 生命周期
| { type: "agent_start" }
| { type: "agent_end"; messages: AgentMessage[] }
// Turn 生命周期
| { type: "turn_start" }
| { type: "turn_end"; message: AgentMessage; toolResults: ToolResultMessage[] }
// Message 生命周期
| { type: "message_start"; message: AgentMessage }
| { type: "message_update"; message: AgentMessage; assistantMessageEvent: AssistantMessageEvent }
| { type: "message_end"; message: AgentMessage }
// Tool 执行生命周期
| { type: "tool_execution_start"; toolCallId: string; toolName: string; args: any }
| { type: "tool_execution_update"; toolCallId: string; toolName: string; args: any; partialResult: any }
| { type: "tool_execution_end"; toolCallId: string; toolName: string; result: any; isError: boolean };agent_end 是最后一个被 emit 的事件,但不意味着 agent 立刻 idle。所有订阅了 agent_end 的 listener 都 settle 之后,agent 才真正进入 idle 状态。这让 listener 有机会在 agent 结束后做清理工作(比如持久化),而 agent 会等它们全部完成。
一次 agent run 的完整事件流
application(coding-agent) packages/agent packages/ai
────────────────────────────────────────────────────────────────────────────
│ │ │
│ agent.prompt(...) ─►runAgentLoop ─► │ │
│ │ │
│ ◄────── agent_start ────────────────│ │
│ ◄────── turn_start ─────────────────│ │
│ * user message * │ │
│ ◄────── message_start ──────────────│ │
│ ◄────── message_end ────────────────│ │
│ │ ── streamSimple(...) ──► │
│ * assistant message1 * │ │
│ ◄────── message_start ──────────────│ ◄────── start ────────── │
│ ◄────── message_update ─────────────│ ◄────── text_start ───── │
│ ◄────── message_update ─────────────│ ◄────── text_delta ───── │
│ │ ◄────── text_end ─────── │
│ . │ ◄────── thinking_start ─ │
│ . │ ◄────── thinking_delta ─ │
│ . │ ◄────── thinking_end ─── │
│ │ ◄────── toolcall_start ─ │
│ │ ◄────── toolcall_delta ─ │
│ ◄────── message_update ─────────────│ ◄────── toolcall_end ─── │
│ ◄────── message_end ────────────────│ ◄────── done ─────────── │
│ │ │
│ ◄────── tool_execution_start ───────│ │
│ ◄────── tool_execution_update ──────│ │
│ ◄────── tool_execution_end ─────────│ │
│ * toolResult message * │ │
│ ◄────── message_start ─────────────│ │
│ ◄────── message_end ──────────────│ │
│ ◄────── turn_end ───────────────────│ │
│ │ │
│ ◄────── turn_start ─────────────────│ messages with toolResult │
│ │ ── streamSimple(...) ──► │
│ * assistant message2 * │ │
│ ◄────── message_start ──────────────│ ◄────── start ────────── │
│ ◄───── message_update ─────────────│ ◄────── text_start ───── │
│ ◄───── ... ─────────────│ ◄────── text_delta ───── │
│ ◄───── message_update ─────────────│ ◄────── text_end ─────── │
│ ◄───── message_end ────────────────│ ◄────── done ─────────── │
│ ◄───── turn_end ───────────────────│ │
│ ◄───── agent_end ──────────────────│ │无状态意味着什么
packages/ai 和 packages/agent 合在一起,完成了从“用户输入”到“agent idle”的全过程。但它们是无状态的:一旦结束就真的结束了,不持久化任何东西,不记得上一次对话的内容、跑了什么工具、得出什么结论。这些"记忆"相关的问题,都是外层 packages/coding-agent 的工作。
下一篇,我们聚焦到应用层。