【π】一个生产级 Coding Agent Harness 长什么样
学习一个项目,最快的方式是从最小例子入手,感受它解决的是什么问题。然后再去看完整实现,理解它如何把问题解决得优雅。
这个系列要讲的是 pi-mono,是一个 TypeScript 写成的生产级 coding agent harness。作者是 mariozechner,花了三年时间在各种 agent 项目里踩坑后自研的个人工具,现在是 openclaw 的 agent 内核。
系列分三篇,这是第一篇。
什么是 Coding Agent Harness
直接调 LLM API,你能做到:发一段文字,收一段回复。模型在原地等着你喂内容,喂完它就结束了。
但 coding agent 要做的事不同:用户说"帮我把登录逻辑改成用 OAuth",agent 需要理解这个请求、读懂项目里的现有代码、调用 bash 执行测试、写文件、最后告诉用户结果。这是一个多轮交互的循环,模型要在整个过程中持续运转。
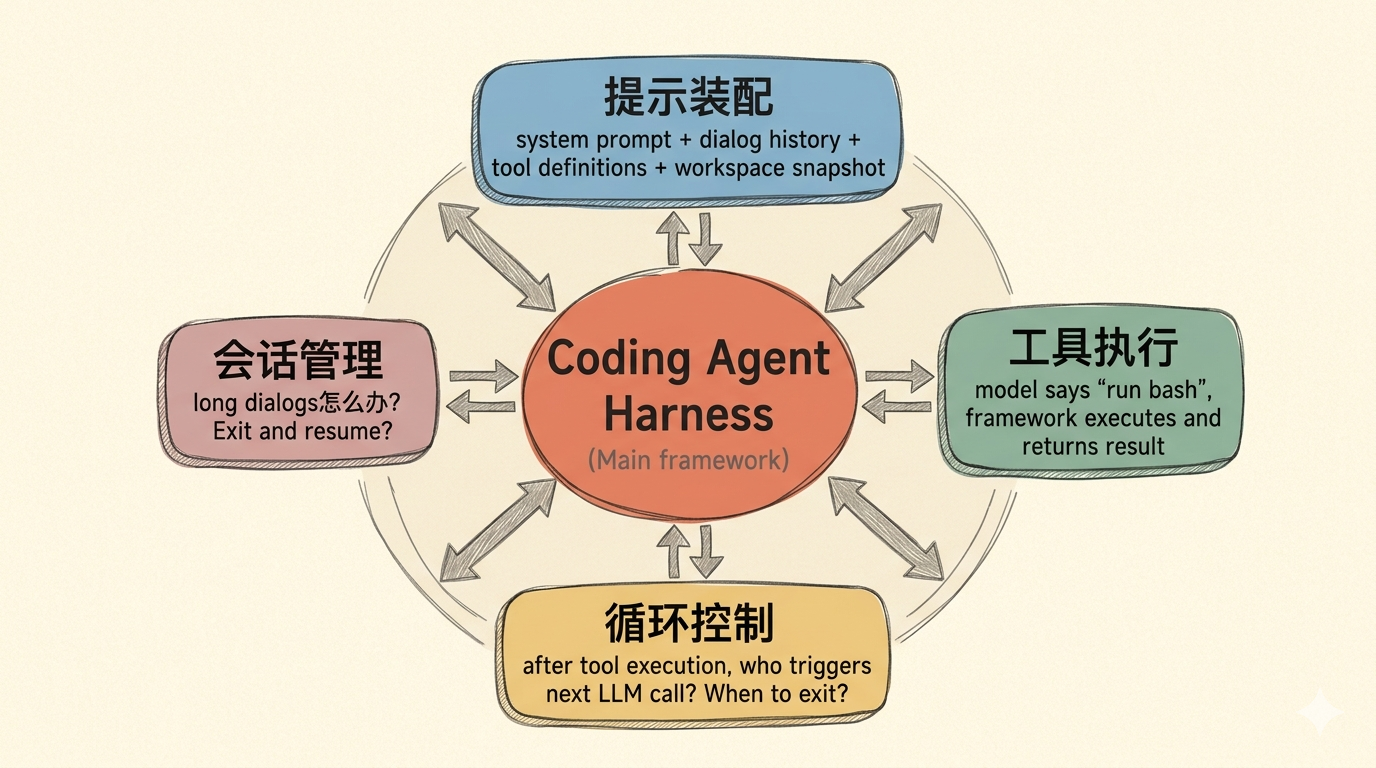
Harness 就是这个循环的框架。它负责:
- Prompt 组装:把系统提示、对话历史、工具定义、workspace 快照拼成完整的请求
- 工具执行:模型说"我要执行 bash",框架负责实际运行并把结果返回
- 循环控制:工具执行完后,谁来触发下一轮 LLM 调用?循环何时退出?
- Session 管理:对话太长了怎么办?退出后怎么恢复?
直接调 API,以上这些全要自己做。Harness 把这些封装好,你只需要关心"我的 agent 要解决什么问题"。
最小示例:600 行里的基本循环
理解 agent harness 最快的方式是看一个最小实现。mini-coding-agent 是 Sebastian Raschka 写的一个 600 行教学级 Python 项目,只有一个文件,完整实现了一个 coding agent 的基本循环。
核心是这个 prompt() 方法,每次用户输入都会调用它来构建发给 LLM 的完整 prompt:
def prompt(self, user_message):
return f"""
{self.prefix} # 静态前缀:工具定义 + 规则 + workspace 快照
{self.memory_text()} # 动态记忆:task / files / notes
Transcript:
{self.history_text()} # 操作流水:用户输入、模型返回、工具调用和结果
Current user request:
{user_message} # 用户当前输入
"""prefix 是静态的,在 Agent 初始化时构建一次,之后每轮复用。它包含:角色描述、工具清单(list_files / read_file / search / run_shell / write_file / patch_file)、响应格式示例,以及 workspace 快照,指当前项目状态的一组关键信息,包括当前分支、git status、最近 commits 等,帮助模型了解代码库的基本情况。
循环的执行路径非常直接:
用户输入
→ 拼 prompt
→ 发给 LLM
→ 解析输出(<tool> 或 <final>)
→ 执行工具或输出最终结果
→ 工具结果写回 history
→ 回到第一步工具执行有审批机制。write_file、run_shell、patch_file 标记为 risky,approval_policy 为 "ask" 时,执行前会弹出 y/N 确认("auto" 直接放行,"never" 直接拒绝)。
这个循环跑通了一个最小可行的 coding agent。但它只解决了"能跑"的问题。
600 行做不到的事
600 行教给我们的:agent harness = prompt 循环 + 工具执行。理解了这个,就能继续往下了。
生产级场景会抛出哪些问题?
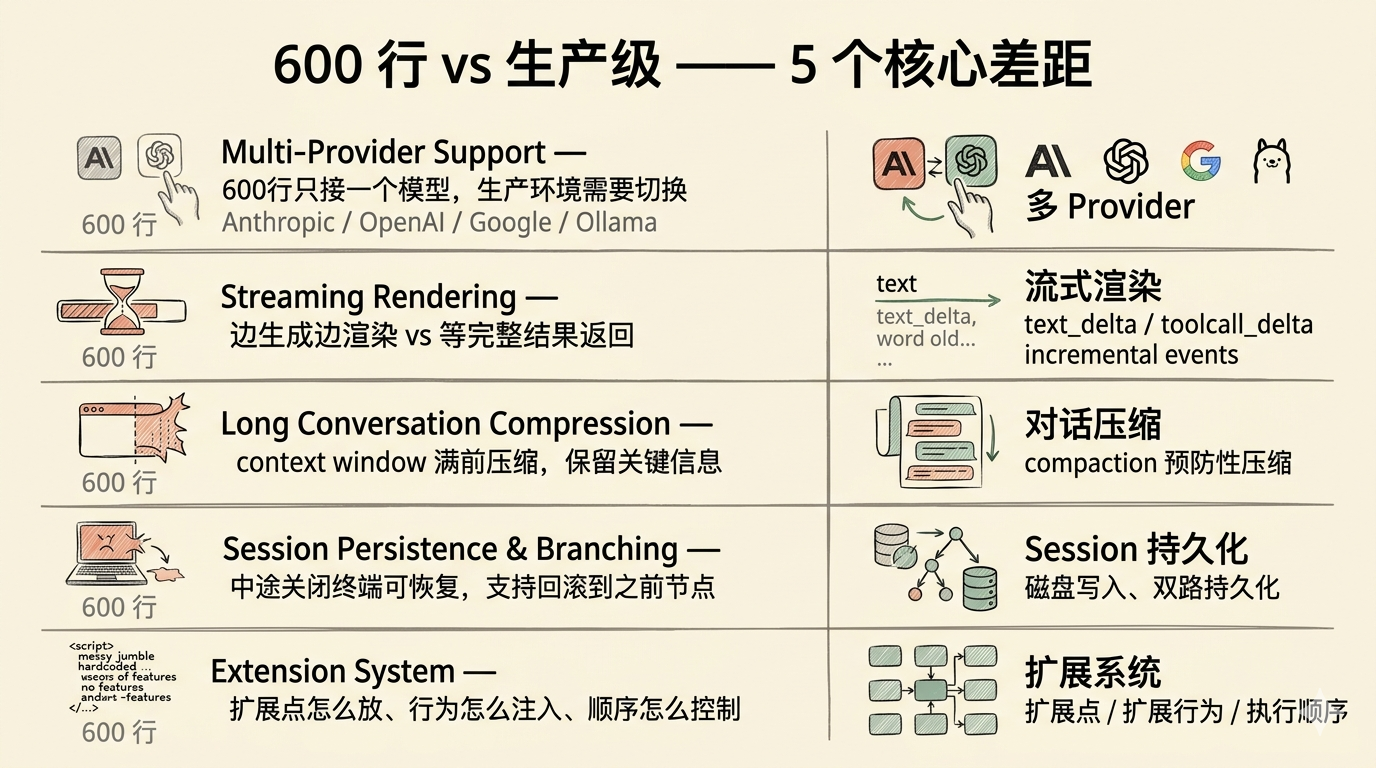
多 provider 支持。 provider 在这里指模型服务商,如 Anthropic(Claude 系列)、OpenAI(GPT 系列)、Google(Gemini 系列)等。mini-coding-agent 只接了一个模型(通过 model_client 注入)。实际使用中,你可能想同时用多个 provider,或者在不同场景下切换不同模型,甚至想接 self-hosted 的 Ollama。各 provider 的 API 格式、URL、认证方式各不相同,这些差异如果每个调用点都处理,维护成本会急剧增加,代码会迅速膨胀。
流式渲染。 mini-coding-agent 的 LLM 输出是等完整结果返回后才显示。体验更好的是边生成边渲染:用户看到"模型在打字",而不是等一个"正在思考中"。这需要框架在 LLM 流式输出的每一步都能触发 UI 更新,框架必须把 provider 返回的切片数据实时转发给渲染层,中间的协议转换和数据分片都要处理好。
长对话压缩。 一个 session 可能持续几十轮对话。对话历史越来越长,会塞满 context window。需要在合适的时机压缩历史,保留关键信息,腾出空间给新的交互。这里的难点在于:压缩的粒度怎么定?保留什么、丢弃什么、依据什么原则?压缩后要保证对话的语义连贯性,不能让模型觉得上下文突然跳变。
Session 持久化与分支。 用户可能中途关闭终端。再次打开时,对话要能恢复。恢复后用户可能想"回到之前的某个节点重新来",这意味着 session 要支持回滚。
扩展系统。 不同用户的项目有不同的上下文和操作习惯。如果 agent harness 不支持扩展,所有特殊需求都只能改核心代码,很快就会变成一锅粥。扩展点放在哪里、扩展行为怎么注入、扩展之间的执行顺序怎么控制,这些问题都是需要拓展系统考虑的,解决不好,扩展系统反而会成为新的耦合来源。
这些不是边角料需求,是生产级工具必须面对的核心问题。pi-mono 的回答是:用分层架构逐层解决,每层各司其职,层与层之间有清晰的抽象边界。
pi-mono:7 个包的 Monorepo
pi-mono 不只是一个包。它是一个 TypeScript monorepo,包含 7 个包:
pi-tui (独立,无其他依赖)
pi-ai (基础层)
├─ pi-agent-core
│ ├─ pi-coding-agent (使用 pi-tui)
│ │ └─ pi-mom (Slack bot)
│ └─ pi-pods (GPU 管理)
└─ pi-web-ui (浏览器 chat UI)我们的系列只聚焦核心 3 层:
| 包 | 职责 |
|---|---|
packages/ai | 一次无状态的 LLM 调用。统一 10+ 个 provider 的 API 格式,处理流式事件协议 |
packages/agent | 一个完整的 agent turn。循环控制、工具执行、事件 emit |
packages/coding-agent | 一个有状态的编码会话。Session 持久化、compaction、扩展系统 |
核心三层各自做到了什么边界
packages/ai 的边界:一次无状态的 LLM 调用。它接收模型配置、对话上下文、工具定义,返回一个增量事件流。它不执行工具、不做循环、不维护状态。调用结束,一切结束。
packages/agent 的边界:一个完整的 agent turn。它接管从"用户输入"到"agent idle"的全过程。但它不知道 session 是什么、compaction 是什么、system prompt 怎么构建,这些是外部系统的事。
packages/coding-agent 的边界:一个有状态的编码会话。它管理 session 生命周期、持久化、对话压缩、slash command、skill 扩展。它调用 packages/agent 完成实际的 agent 循环,但不关心流式传输细节。
每层的核心事件类型决定了它的设计边界:
// packages/ai:流式事件的 12 种类型
type AssistantMessageEvent =
| { type: "start"; partial: AssistantMessage }
| { type: "text_start"; contentIndex: number; partial: AssistantMessage }
| { type: "text_delta"; contentIndex: number; delta: string; partial: AssistantMessage }
| { type: "text_end"; contentIndex: number; content: string; partial: AssistantMessage }
| { type: "toolcall_start"; contentIndex: number; partial: AssistantMessage }
| { type: "toolcall_delta"; contentIndex: number; delta: string; partial: AssistantMessage }
| { type: "toolcall_end"; contentIndex: number; toolCall: ToolCall; partial: AssistantMessage }
| { type: "done"; reason: Extract<StopReason, "stop" | "length" | "toolUse">; message: AssistantMessage }
| { type: "error"; reason: Extract<StopReason, "aborted" | "error">; error: AssistantMessage };
// ... 以及 thinking_start / thinking_delta / thinking_endpackages/ai 发出的每一个事件都是增量式的:text_delta 包含一段新文本,toolcall_delta 包含一段新的 JSON 参数(流式解析)。外层可以立即渲染,无需等待完整结果。partial 字段是组装好的全量的 AssistantMessage,方便外层使用。
// packages/agent:生命周期事件
type AgentEvent =
// Agent lifecycle
| { type: "agent_start" }
// Turn lifecycle - a turn is one assistant response + any tool calls/results
| { type: "turn_start" }
// Message lifecycle - emitted for user, assistant, and toolResult messages
| { type: "message_start"; message: AgentMessage }
// Only emitted for assistant messages during streaming
| { type: "message_update"; message: AgentMessage; assistantMessageEvent: AssistantMessageEvent }
| { type: "message_end"; message: AgentMessage }
// Tool execution lifecycle
| { type: "tool_execution_start"; toolCallId: string; toolName: string; args: any }
| { type: "tool_execution_update"; toolCallId: string; toolName: string; args: any; partialResult: any }
| { type: "tool_execution_end"; toolCallId: string; toolName: string; result: any; isError: boolean };
| { type: "turn_end"; message: AgentMessage; toolResults: ToolResultMessage[] }
| { type: "agent_end"; messages: AgentMessage[] }packages/agent 发出的事件分为四类:
- Agent lifecycle 控制整个会话的起止:
agent_start标志一次会话开始,agent_end在会话结束时把完整消息列表吐出来 - Turn lifecycle 是一次标准回合:用户说一句话 → 模型生成回复 → 工具执行 → 工具结果返回 → 模型再回复。"turn_start" 标志新回合开始,"turn_end" 标志这个回合的工具调用和结果全部回收完毕
- Message lifecycle 跟踪每条消息的生命周期:每条消息(用户输入、模型回复、工具结果)都会经历 start → update(流式输出时的增量更新)→ end 三步
- Tool execution lifecycle 跟踪每个工具调用的执行过程:
tool_execution_start开始执行、tool_execution_update持续输出中间结果、tool_execution_end执行完毕并返回结果
一个 Agent session 包含多个 Turn,一个 Turn 包含多条 Message 和多个 Tool execution。
观察者模式让整个系统更加解耦:每一层只负责发出事件,谁订阅这些事件、怎么处理这些事件完全由外部系统决定。
一次请求的中等精度追踪
我们已经有 pi 项目的全景了,现在让我们用一次具体的请求模拟一遍。
初始化 system prompt
会话初始化时,系统先拼装一份完整的 system prompt,作为给模型的"行为说明书"。由 buildSystemPrompt() 拼装。如果项目里有 .pi/SYSTEM.md 或用户全局配置了 ~/.pi/agent/SYSTEM.md,就直接用;没有的话按默认逻辑拼接:角色声明 → 可用工具列表 → 动态生成的 guidelines → skills 索引 → 当前时间和工作目录。
Skills 这里多说一句:LLM 看到的是一个 XML 索引,只有"有哪些技能可用"和简单描述,真正的技能正文在用到时才触发展开。渐进式披露 避免了每次请求都把大量技能文档塞进 context。
用户输入: "帮我给这个项目加一个登录功能"
第一步:输入展开与 context 检查
输入先经过一道展开层:如果以 / 开头,会被识别为 slash command(/skill 展开技能、/template 展开模板),普通文本直接透传。
展开后,系统估算当前对话已经占用了多少 token。如果快要塞满 context window,会先触发一次压缩(compaction),把历史对话精简后再继续。压缩是预防性的,不影响用户当前输入的处理。
第二步:进入 agent 循环
带着消息数组,请求进入 packages/agent 的 runAgentLoop。
这个循环是双重 while 结构:内层循环负责工具调用,模型说"我要读文件",框架去执行,然后把结果返回给模型,模型再决定下一步;只要还有工具在调用,内层就一直跑。外层循环负责跟进,内层跑完后,检查系统或用户有没有提出新的问题或要求,有的话就追加进对话继续;没有就退出,整个 agent 进入 idle 状态。
工具执行默认采用"全部启动、按序回收"策略:多个工具调用同时开始执行,但返回给模型时必须按模型提出的顺序返回结果,即便 A 工具先完成、B 工具后完成,也必须等 B 完成后按 B→A 的顺序返回。这是因为模型是根据调用顺序来对应工具调用和返回结果的,如果顺序乱了,模型会把 B 的结果误当作 A 的结果,导致逻辑错乱。
第三步:穿越到 packages/ai,发给 LLM
packages/agent 调 packages/ai 的 streamSimple() 函数,ai 层根据配置的平台(Anthropic / OpenAI / Google / Ollama 等)找到对应适配器。适配器负责把统一格式的请求翻译成各平台自己的格式,不同公司的 API 细节完全不同,这个翻译层让外层不需要关心底层差异。
请求发出后,LLM 的响应以流式事件返回。packages/ai 把这些事件翻译成统一的 AssistantMessageEvent 协议,抛给外层。外层收到的是一个个增量片段(text_delta、toolcall_delta),可以立即渲染,不用等完整结果。
第四步:事件回调,双路持久化
packages/agent 收到每个事件后做两件事:更新自己的内部状态,以及通知所有注册过的 listener。
packages/coding-agent 是最重要的 listener。它收到事件后干三件事:把消息写入磁盘(持久化)、转发给扩展(如果有 hook 注册)、检查需不需要自动重试或自动压缩。
这里有个细节:运行时状态和持久化状态是两套独立维护的列表,它们几乎同时更新,但来源不同。在 compaction、session 恢复、或切换分支时两者强制同步,其他时间各长各的。
这个系列的路线图
现在你知道了:
- agent harness 是什么(prompt 组装 + 工具执行 + 循环控制 + session 管理)
- 核心架构各层做到了什么边界
- 一次请求如何在 agent harness 中流动
接下来的两篇文章会分别聚焦到运行时层(packages/ai 和 packages/agent)和应用层(packages/coding-agent),看看它们分别是怎么实现的。